#3-1 Content-Comment Count Partitioning & Text Feature Comparison
- We analyzed the relationship between article content and comment counts to identify features that influence public response in drug-related news articles.
- We attempted feature extraction by partitioning and comparing articles with high comment counts versus low comment counts under various conditions.
- Main Analysis Methods: LDA topic comparison, TF-IDF and Word2vec value comparison, and word cloud visualization
Condition:
1) Analysis of content differences between articles with and without comments
2) Analysis of content differences between articles with 10+ comments versus 1-9 comments (threshold of 10 chosen to create similarly sized groups) - The feature distinctions were more pronounced when grouping by the 10-comment threshold compared to the presence/absence of comments. The following details the analysis process for condition 2 (condition 1 process omitted).
import pandas as pd
# Load the modified data
data = pd.read_csv("final_combined.csv")
# Remove commas from the comment_count column
# data['comment_count'] = data['comment_count'].str.replace(',', '')
# Convert the comment_count column to floats
data['comment_count'] = data['comment_count'].astype(float)
# Fill missing values with 0
data['comment_count'].fillna(0, inplace=True)
# Convert the comment_count column to integers
data['comment_count'] = data['comment_count'].astype(int)
data_without = data[data['comment_count'] == 0]
data_with = data[data['comment_count'] >= 1]
# Save the classified data to separate CSV files
data_without.to_csv("data_without_comments.csv", index=False)
data_with.to_csv("data_with_comments.csv", index=False)print(len(data_without))
print(len(data_with))921
import pandas as pd
from gensim.corpora import Dictionary
from gensim.models import LdaModel
import pyLDAvis.gensim_models as gensimvis
import pyLDAvis
import matplotlib.pyplot as plt
from gensim.models.coherencemodel import CoherenceModel
import re
# Read the CSV files
data_without = pd.read_csv("data_without_comments.csv")
data_with = pd.read_csv("data_with_comments.csv")
# Text cleaning function: Removes all characters except Korean
def text_cleaning(text):
# Extract only Korean text using Korean regular expression
hangul = re.compile('[^ ㄱ-ㅣ가-힣]+')
result = hangul.sub('', text)
return result
def split_text(text):
tokens = text.split()
return tokens
# Check the processed text after applying text cleaning
data_without['content_cleaned'] = data_without['content_tokenized'].apply(text_cleaning)
data_with['content_cleaned'] = data_with['content_tokenized'].apply(text_cleaning)
data_without['processed'] = data_without['content_cleaned'].apply(split_text)
data_with['processed'] = data_with['content_cleaned'].apply(split_text)
# Create the dictionary and corpus for each dataset
dictionary_data_without = Dictionary(data_without['processed'])
dictionary_data_with = Dictionary(data_with['processed'])
corpus_data_without = [dictionary_data_without.doc2bow(doc) for doc in data_without['processed']]
corpus_data_with = [dictionary_data_with.doc2bow(doc) for doc in data_with['processed']]
# Set topic range
topic_range = range(4, 20, 1)
# Compute perplexity
def compute_perplexity(dictionary, corpus, num_topics):
model = LdaModel(corpus=corpus, num_topics=num_topics, id2word=dictionary, passes=20, random_state=42)
return model.log_perplexity(corpus)
# Compute coherence score
def compute_coherence_score(dictionary, corpus, tokens, num_topics):
model = LdaModel(corpus=corpus, num_topics=num_topics, id2word=dictionary, passes=20, random_state=42)
coherence_model = CoherenceModel(model=model, texts=tokens, dictionary=dictionary, coherence='c_v')
return coherence_model.get_coherence()
# Calculate scores while displaying progress
def calculate_scores(num_topics, dictionary, corpus, tokens):
perplexity = compute_perplexity(dictionary, corpus, num_topics)
coherence = compute_coherence_score(dictionary, corpus, tokens, num_topics)
print(f"Completed: {num_topics} Topics - Perplexity: {perplexity}, Coherence: {coherence}")
return perplexity, coherence
# Calculate and plot scores for each dataset
for dataset_name, dictionary, corpus, tokens, xlabel in [('data_without', dictionary_data_without, corpus_data_without, data_without['processed'], "Group A(0 comments)"),
('data_with', dictionary_data_with, corpus_data_with, data_with['processed'], "Group B(1 or more comments)")]:
# Calculate scores within the topic range
scores = [calculate_scores(num_topics, dictionary, corpus, tokens) for num_topics in topic_range]
# Separate results
perplexity_scores, coherence_scores = zip(*scores)
# Plot the graph
fig, ax1 = plt.subplots()
ax1.set_title(dataset_name)
ax1.set_xlabel(xlabel)
ax1.set_ylabel("Perplexity", color="tab:red")
ax1.plot(topic_range, perplexity_scores, color="tab:red")
ax1.tick_params(axis="y", labelcolor="tab:red")
ax2 = ax1.twinx()
ax2.set_ylabel("Coherence Score", color="tab:blue")
ax2.plot(topic_range, coherence_scores, color="tab:blue")
ax2.tick_params(axis="y", labelcolor="tab:blue")
fig.tight_layout()
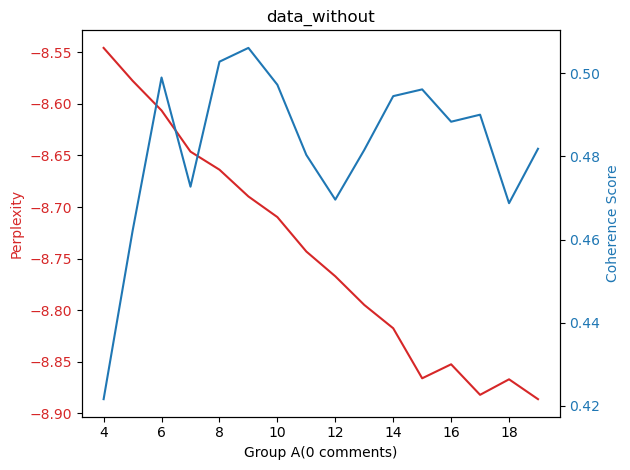
plt.show()Completed: 5 Topics - Perplexity: -8.577578774403676, Coherence: 0.4620644757299998
Completed: 6 Topics - Perplexity: -8.606391782855125, Coherence: 0.4989608286375847
Completed: 7 Topics - Perplexity: -8.646308482844377, Coherence: 0.47271136551680615
Completed: 8 Topics - Perplexity: -8.663817816326693, Coherence: 0.5027667077977429
Completed: 9 Topics - Perplexity: -8.689776465706036, Coherence: 0.5060817580934436
Completed: 10 Topics - Perplexity: -8.709782955436458, Coherence: 0.49721710188030466
Completed: 11 Topics - Perplexity: -8.74316420376054, Coherence: 0.48034924117893885
Completed: 12 Topics - Perplexity: -8.767182995898786, Coherence: 0.4695984058212764
Completed: 13 Topics - Perplexity: -8.794928980433408, Coherence: 0.48154107143299824
Completed: 14 Topics - Perplexity: -8.817581417762145, Coherence: 0.4944833689685558
Completed: 15 Topics - Perplexity: -8.866092678605636, Coherence: 0.49610663932191745
Completed: 16 Topics - Perplexity: -8.852518662538598, Coherence: 0.48833192206859
Completed: 17 Topics - Perplexity: -8.882117869860314, Coherence: 0.49002103047078027
Completed: 18 Topics - Perplexity: -8.867069046046932, Coherence: 0.4687427534518663
Completed: 19 Topics - Perplexity: -8.886317207038648, Coherence: 0.4818265205321448
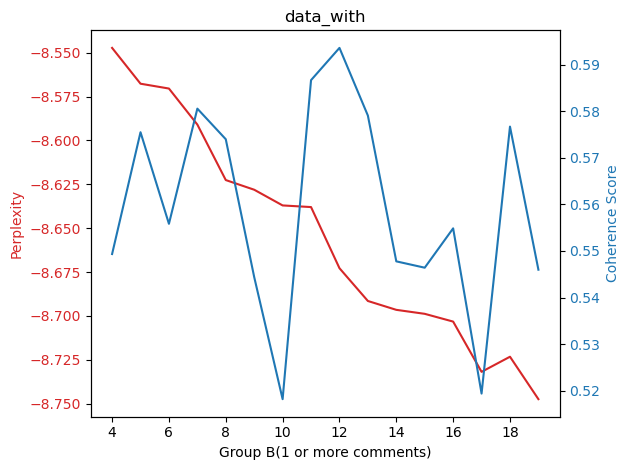
Completed: 5 Topics - Perplexity: -8.567639841611424, Coherence: 0.5754764423875504
Completed: 6 Topics - Perplexity: -8.570396456641168, Coherence: 0.5558185771577905
Completed: 7 Topics - Perplexity: -8.59093705221008, Coherence: 0.5805389452142407
Completed: 8 Topics - Perplexity: -8.622573382415453, Coherence: 0.5739716140383584
Completed: 9 Topics - Perplexity: -8.628083299560808, Coherence: 0.5443914028972296
Completed: 10 Topics - Perplexity: -8.63703712961173, Coherence: 0.5181798198571119
Completed: 11 Topics - Perplexity: -8.637977256744065, Coherence: 0.586653951720521
Completed: 12 Topics - Perplexity: -8.67282164856564, Coherence: 0.5935768533024314
Completed: 13 Topics - Perplexity: -8.691518545517146, Coherence: 0.5790502427696755
Completed: 14 Topics - Perplexity: -8.696570799775277, Coherence: 0.5477582693213806
Completed: 15 Topics - Perplexity: -8.698841204119976, Coherence: 0.5463965911569338
Completed: 16 Topics - Perplexity: -8.703265972106573, Coherence: 0.554844283567278
Completed: 17 Topics - Perplexity: -8.731919188504026, Coherence: 0.5193776062863881
Completed: 18 Topics - Perplexity: -8.723301467816478, Coherence: 0.5766803515476001
Completed: 19 Topics - Perplexity: -8.74749359031195, Coherence: 0.5459678305914446
# Train the LDA models
lda_data_without = LdaModel(corpus_data_without, id2word=dictionary_data_without, num_topics=9, passes=20, random_state=42)
lda_data_with = LdaModel(corpus_data_with, id2word=dictionary_data_with, num_topics=12, passes=20, random_state=42)
import pyLDAvis
import pyLDAvis.gensim_models as gensimvis
vis_data_without = gensimvis.prepare(lda_data_without, corpus_data_without, dictionary_data_without, mds='mmds', n_jobs=1)
vis_data_with = gensimvis.prepare(lda_data_with, corpus_data_with, dictionary_data_with, mds='mmds', n_jobs=1)for topic in lda_data_without.print_topics(num_topics=9):
topic_num, topic_keywords = topic
print(f"{topic_num} : {topic_keywords}")1 : 0.006*"마약" + 0.003*"범죄" + 0.003*"국민" + 0.002*"필요" + 0.002*"사회" + 0.002*"제조" + 0.002*"투약" + 0.002*"서울" + 0.002*"환자" + 0.002*"보건"
2 : 0.004*"마약" + 0.003*"혐의" + 0.003*"범죄" + 0.003*"해외" + 0.002*"경찰" + 0.002*"정부" + 0.002*"국내" + 0.002*"범행" + 0.002*"조직" + 0.002*"수사"
3 : 0.009*"마약" + 0.007*"범죄" + 0.006*"수사" + 0.006*"유통" + 0.005*"서울" + 0.004*"단속" + 0.004*"경찰" + 0.004*"투약" + 0.004*"검거" + 0.004*"국내"
4 : 0.003*"관리" + 0.003*"마약" + 0.003*"사용" + 0.003*"정신성" + 0.003*"향정신성의약품" + 0.002*"시스템" + 0.002*"유명" + 0.002*"사례" + 0.002*"사진" + 0.002*"투약"
5 : 0.007*"마약" + 0.004*"범죄" + 0.003*"경찰" + 0.003*"국민" + 0.003*"마약범죄" + 0.003*"정부" + 0.003*"중독" + 0.002*"본부" + 0.002*"예방" + 0.002*"위험성"
6 : 0.007*"마약" + 0.003*"경찰" + 0.003*"범죄" + 0.003*"예정" + 0.003*"수사" + 0.003*"문제" + 0.003*"서울" + 0.003*"예방" + 0.003*"사회" + 0.002*"한국"
7 : 0.007*"마약" + 0.005*"필로폰" + 0.004*"조직" + 0.004*"경찰청" + 0.004*"국내" + 0.004*"경찰" + 0.004*"범죄" + 0.004*"수사" + 0.004*"검거" + 0.003*"마약왕"
8 : 0.007*"마약" + 0.007*"강남" + 0.006*"서울" + 0.005*"혐의" + 0.005*"경찰" + 0.004*"수사" + 0.004*"음료" + 0.004*"신고" + 0.004*"행사" + 0.004*"대치"
for topic in lda_data_with.print_topics(num_topics=12):
topic_num, topic_keywords = topic
print(f"{topic_num} : {topic_keywords}")1 : 0.003*"마약" + 0.003*"문제" + 0.002*"범죄" + 0.002*"국민" + 0.002*"의원" + 0.002*"민주당" + 0.002*"유지" + 0.002*"서울" + 0.002*"마약사범" + 0.002*"나라"
2 : 0.006*"마약" + 0.004*"검찰" + 0.004*"혐의" + 0.004*"서울" + 0.004*"수사" + 0.003*"중앙" + 0.003*"지검" + 0.003*"아들" + 0.003*"서울중앙지검" + 0.003*"범죄"
3 : 0.007*"마약" + 0.005*"범죄" + 0.005*"서울" + 0.005*"수사" + 0.004*"검찰" + 0.004*"밀수" + 0.004*"유통" + 0.004*"검찰청" + 0.004*"국내" + 0.003*"조직"
4 : 0.007*"마약" + 0.004*"혐의" + 0.004*"필요" + 0.004*"선고" + 0.003*"투약" + 0.003*"처벌" + 0.003*"중독" + 0.003*"치료" + 0.003*"범죄" + 0.003*"약물"
5 : 0.006*"마약" + 0.004*"거래" + 0.004*"범죄" + 0.004*"경찰" + 0.004*"중독" + 0.003*"투약" + 0.003*"판매" + 0.003*"마약사범" + 0.003*"청소년" + 0.003*"서비스"
6 : 0.003*"멕시코" + 0.003*"미국" + 0.003*"마약" + 0.003*"카르텔" + 0.003*"대통령" + 0.003*"밀매" + 0.002*"작전" + 0.002*"중국" + 0.002*"로페스" + 0.002*"드레스"
7 : 0.006*"마약" + 0.006*"범죄" + 0.005*"수사" + 0.005*"정부" + 0.004*"마약범죄" + 0.004*"마약사범" + 0.004*"서울" + 0.004*"기관" + 0.004*"검찰" + 0.004*"투약"
8 : 0.009*"강남" + 0.008*"마약" + 0.007*"경찰" + 0.007*"서울" + 0.006*"범죄" + 0.006*"수사" + 0.005*"음료" + 0.005*"경찰청" + 0.005*"검거" + 0.005*"학원가"9 : 0.006*"마약" + 0.004*"범죄" + 0.004*"정부" + 0.004*"수사" + 0.004*"대응" + 0.004*"필요" + 0.003*"서울" + 0.003*"국가" + 0.003*"조직" + 0.003*"통폐합"10 : 0.004*"마약" + 0.004*"참사" + 0.004*"이태원" + 0.003*"국민" + 0.003*"국회" + 0.003*"국정" + 0.003*"위원회" + 0.003*"규명" + 0.003*"국정조사" + 0.003*"의원"11 : 0.005*"마약" + 0.005*"수사" + 0.004*"범죄" + 0.003*"검찰" + 0.003*"정부" + 0.003*"국가" + 0.003*"전쟁" + 0.003*"서울" + 0.003*"검찰청" + 0.003*"법무부"
pyLDAvis.display(vis_data_without)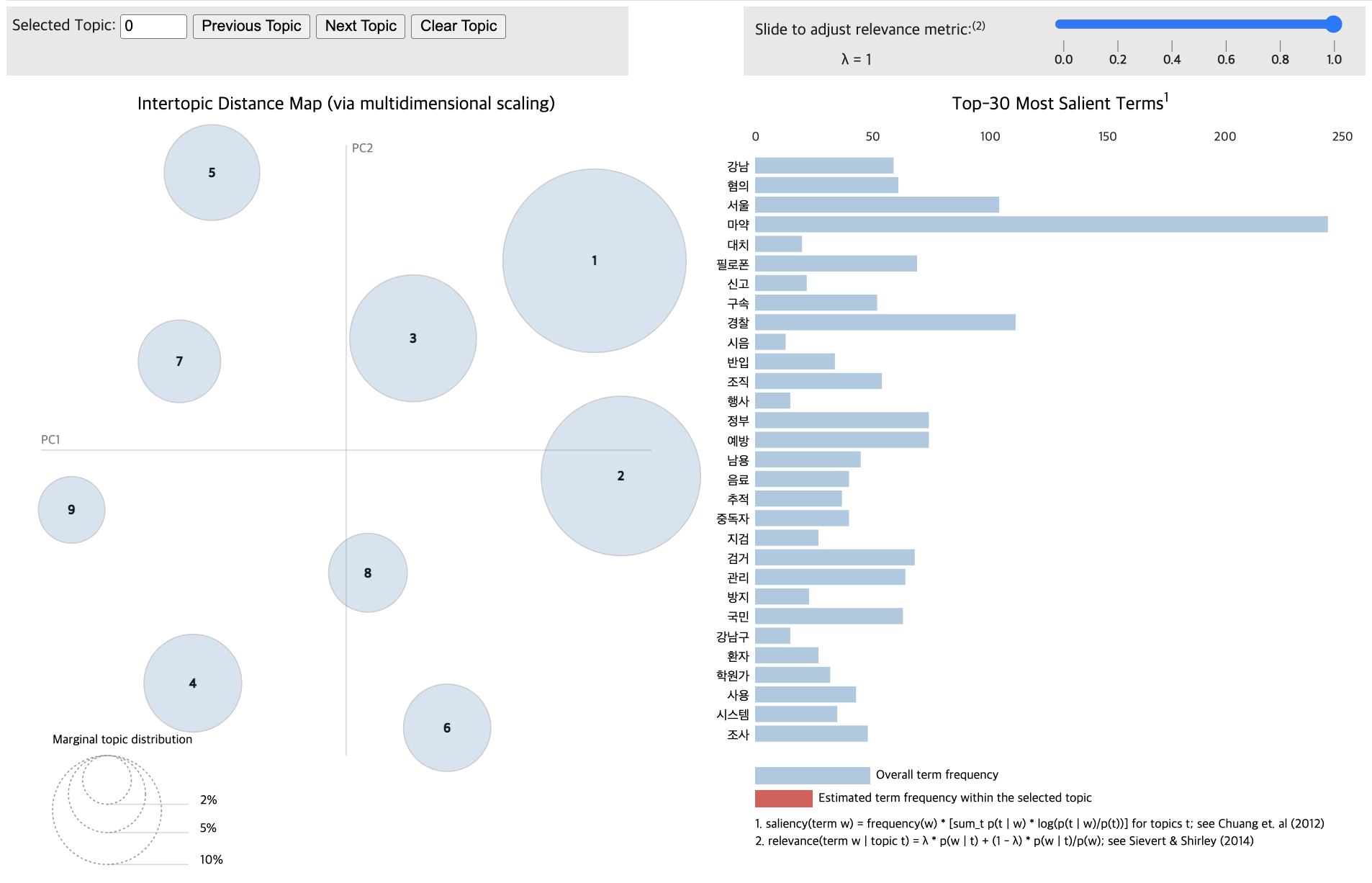
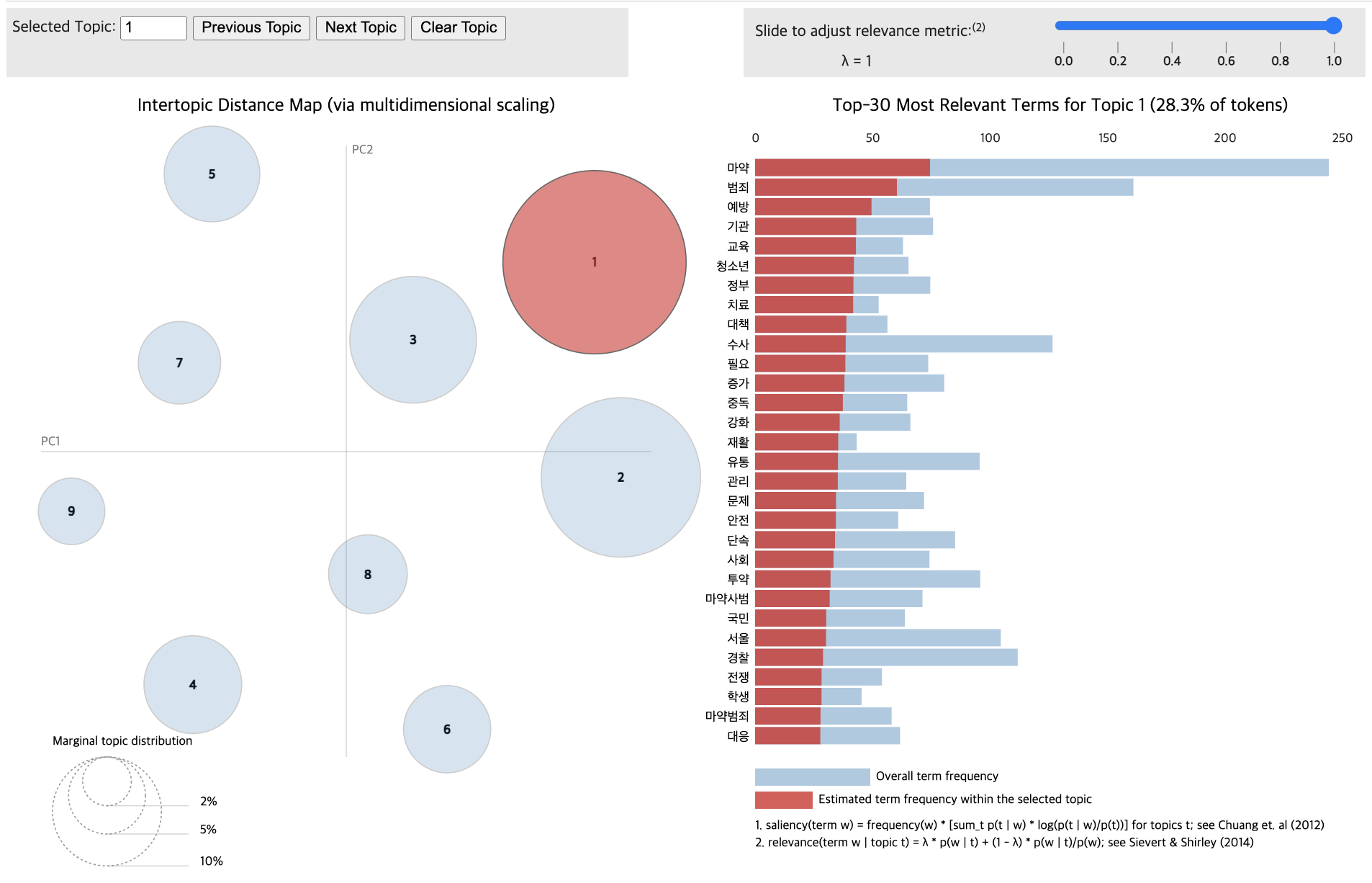
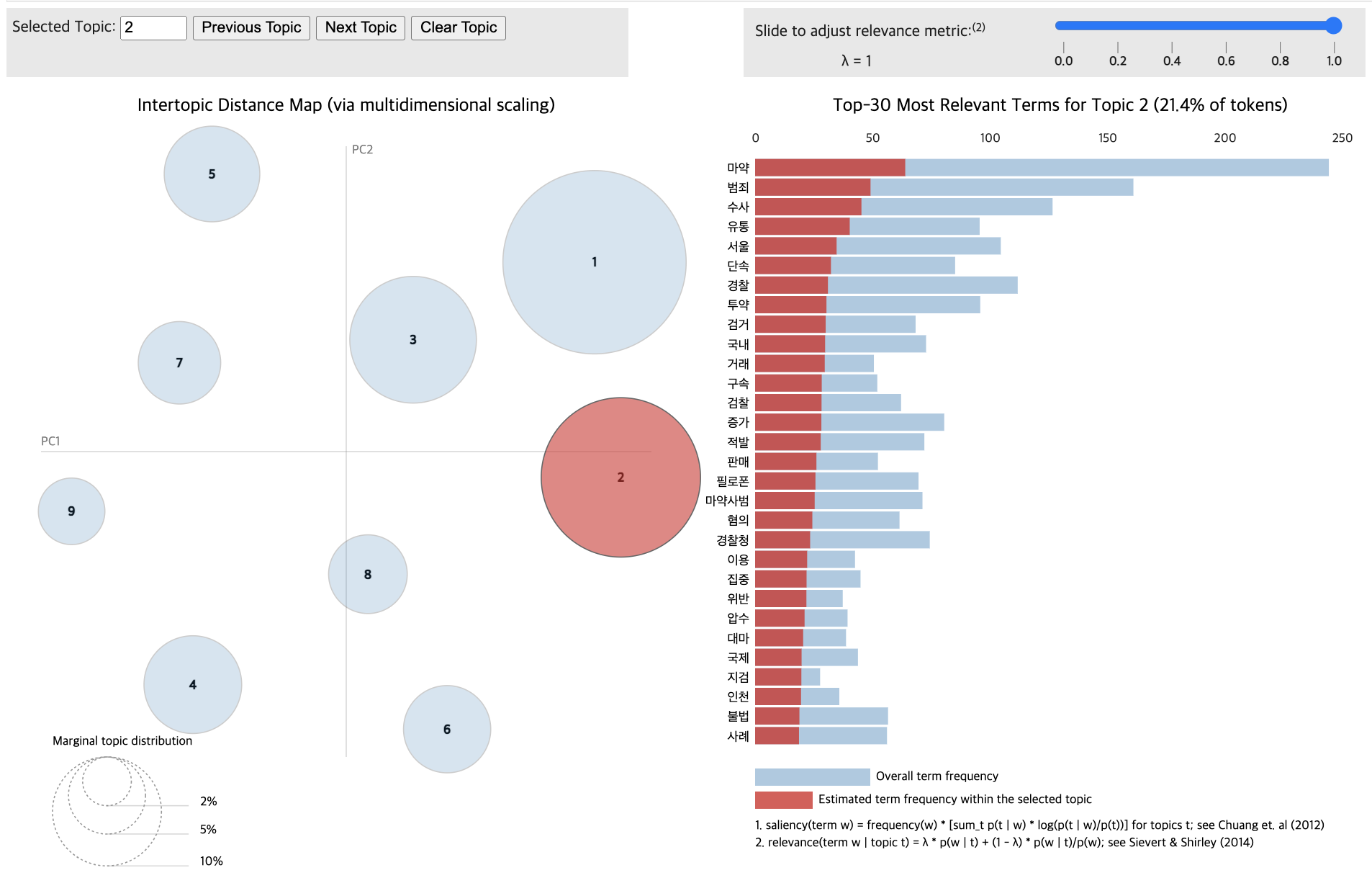
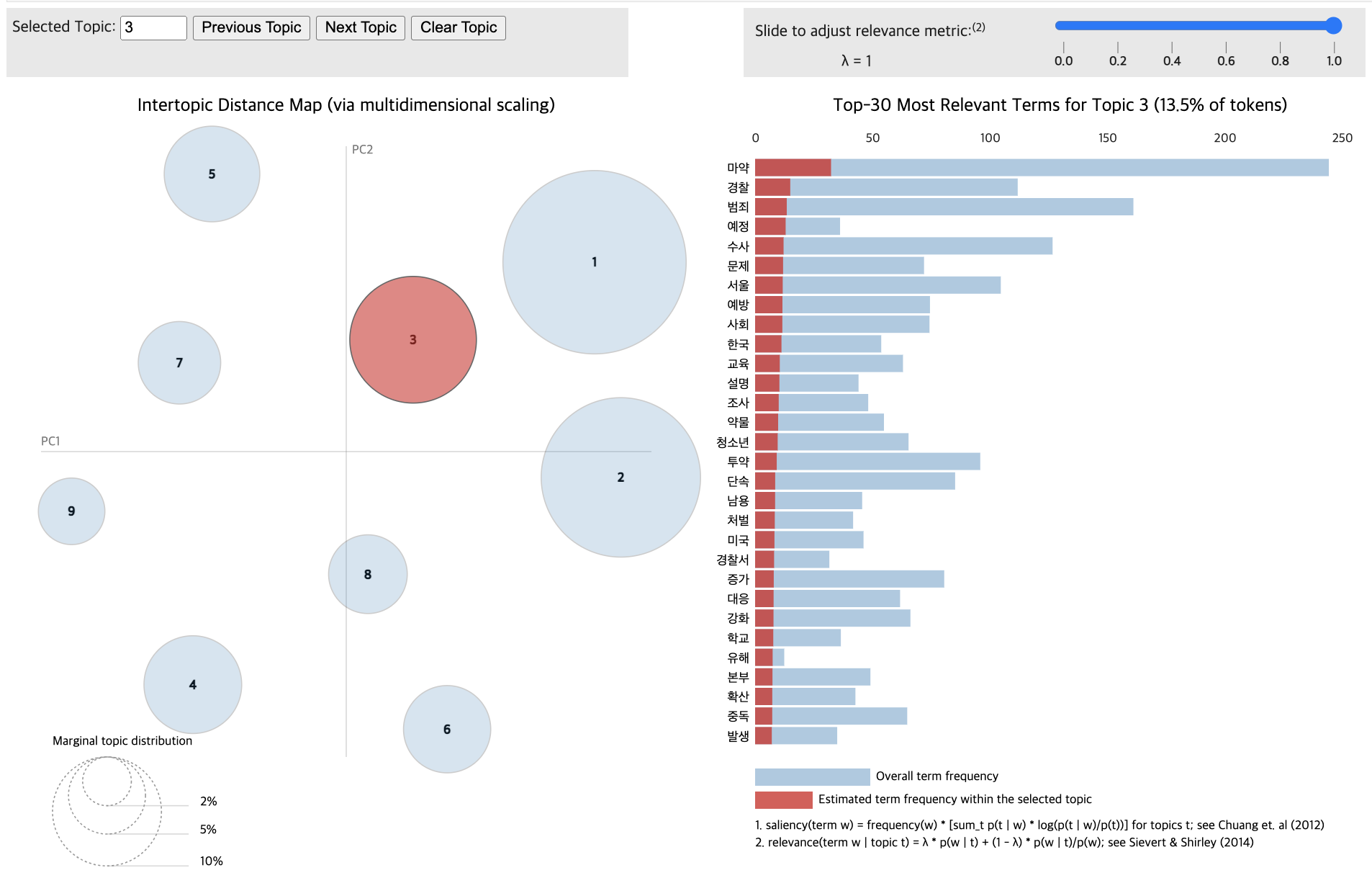
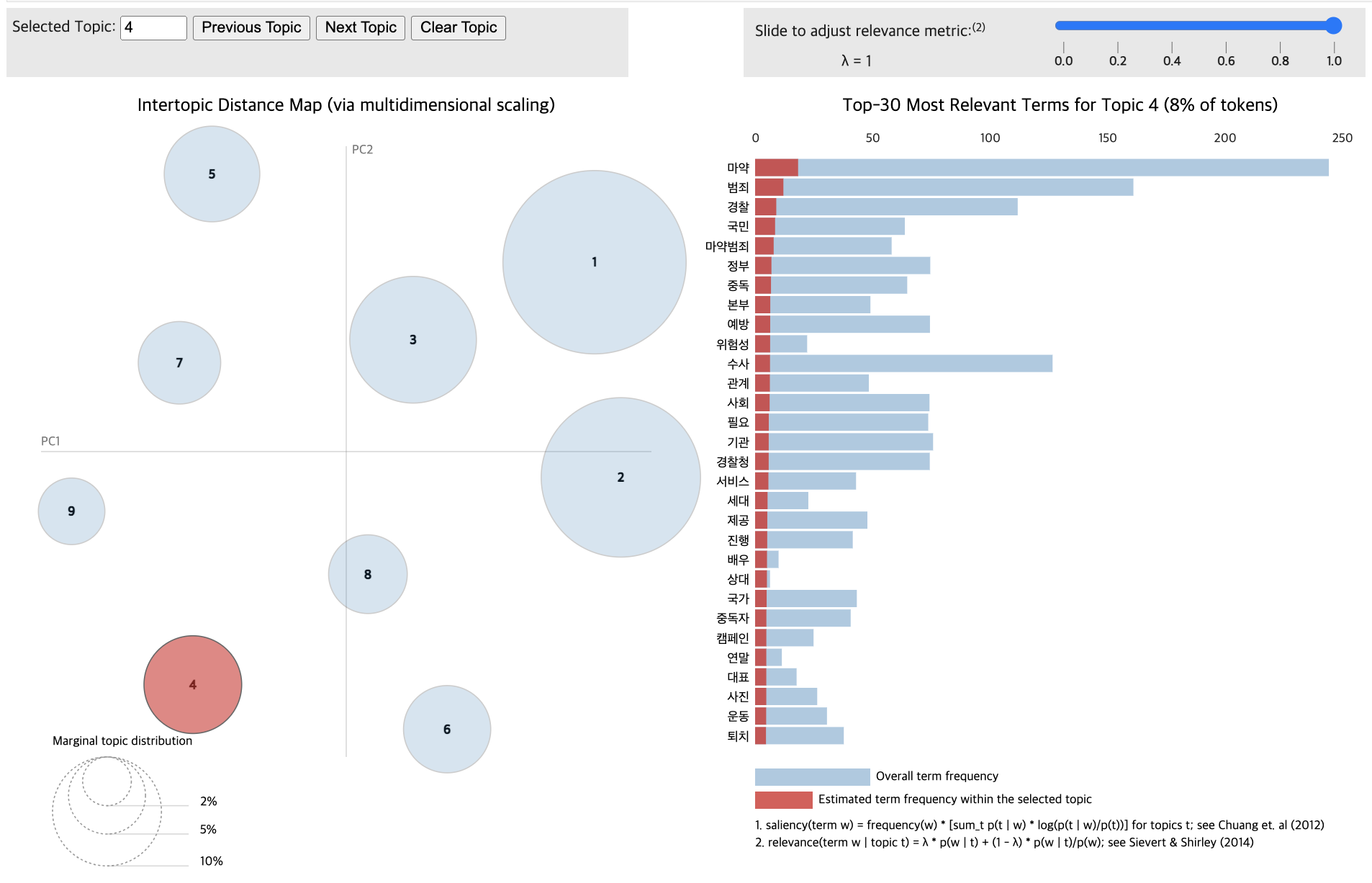
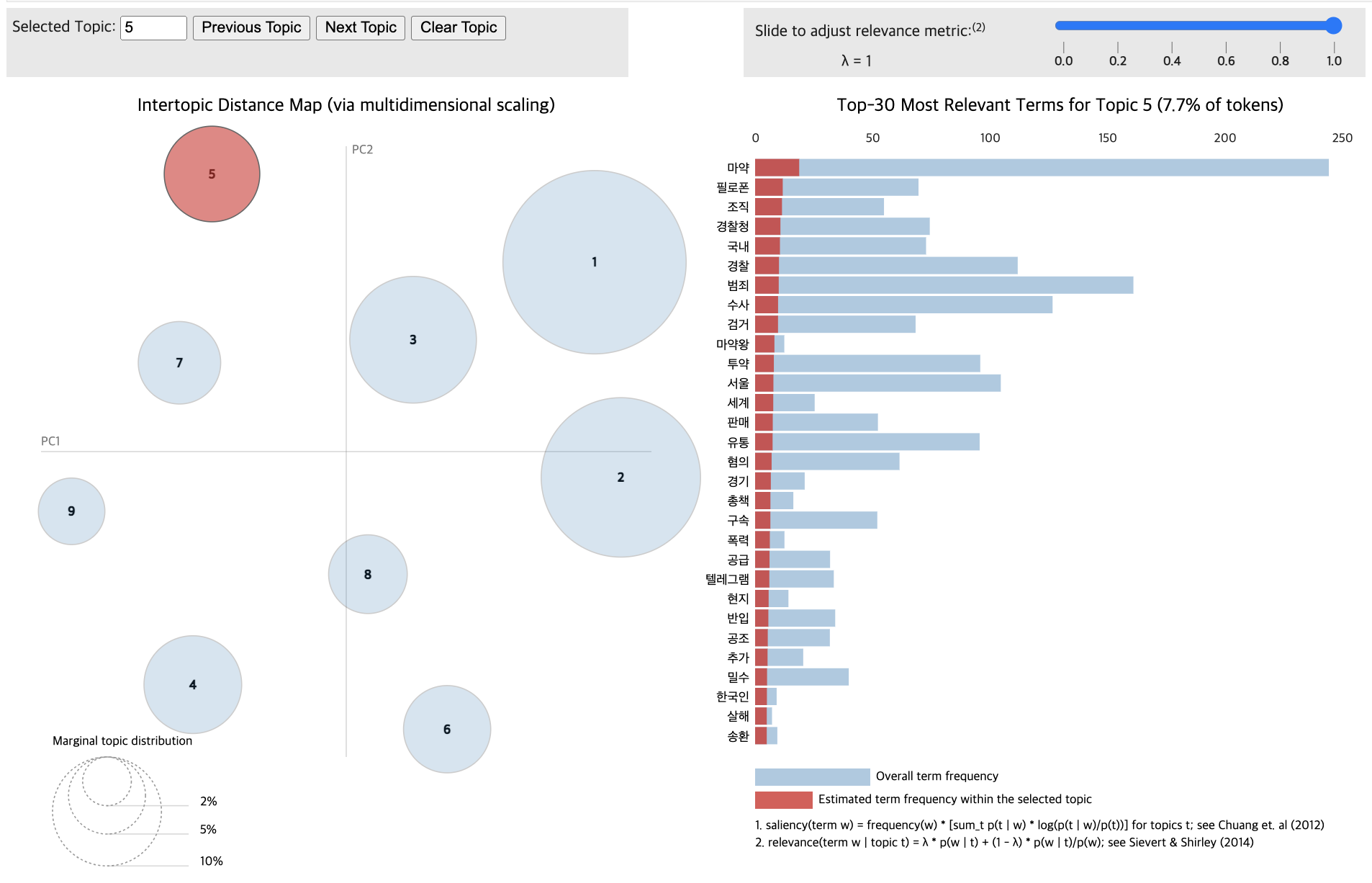
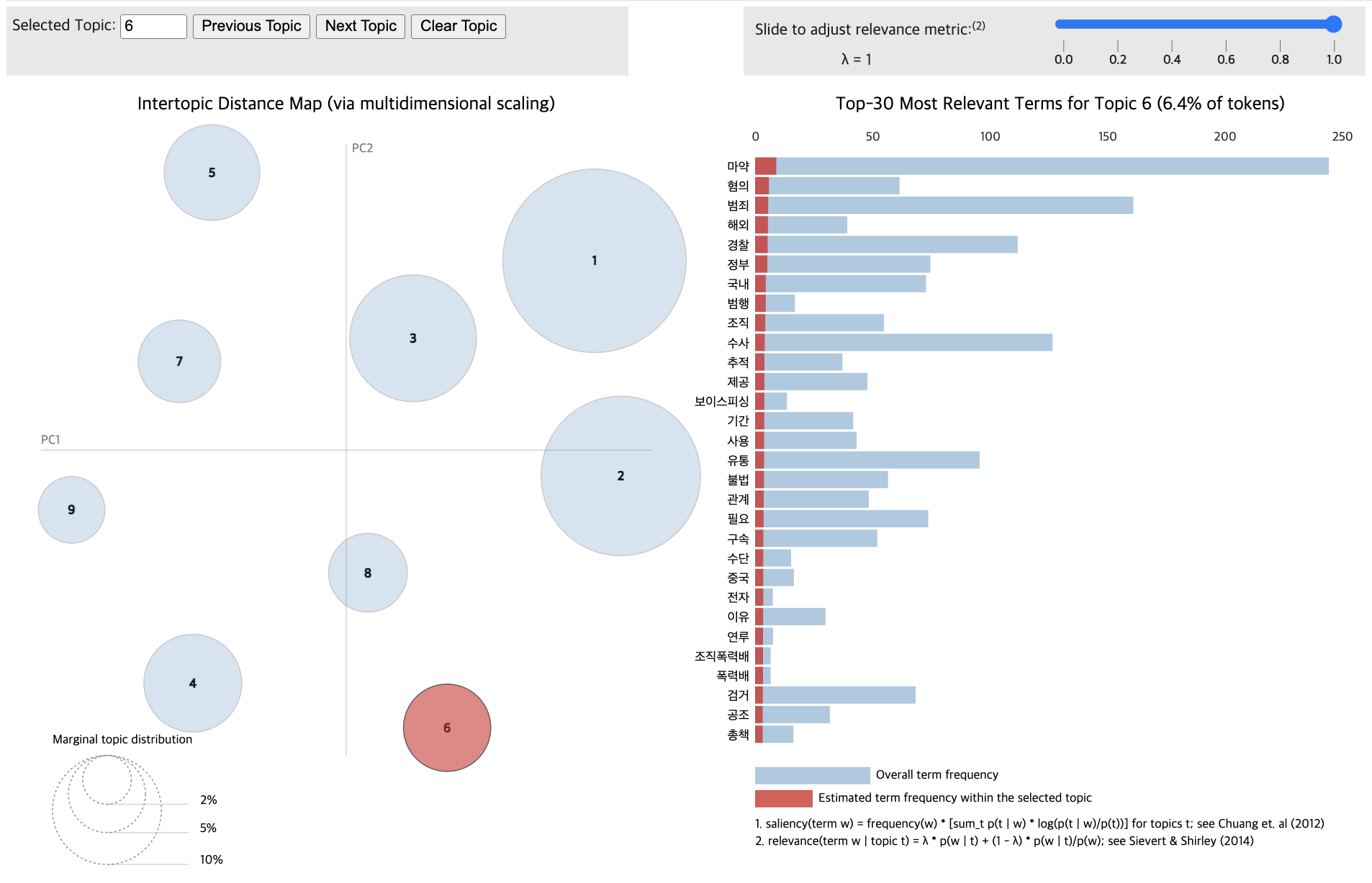
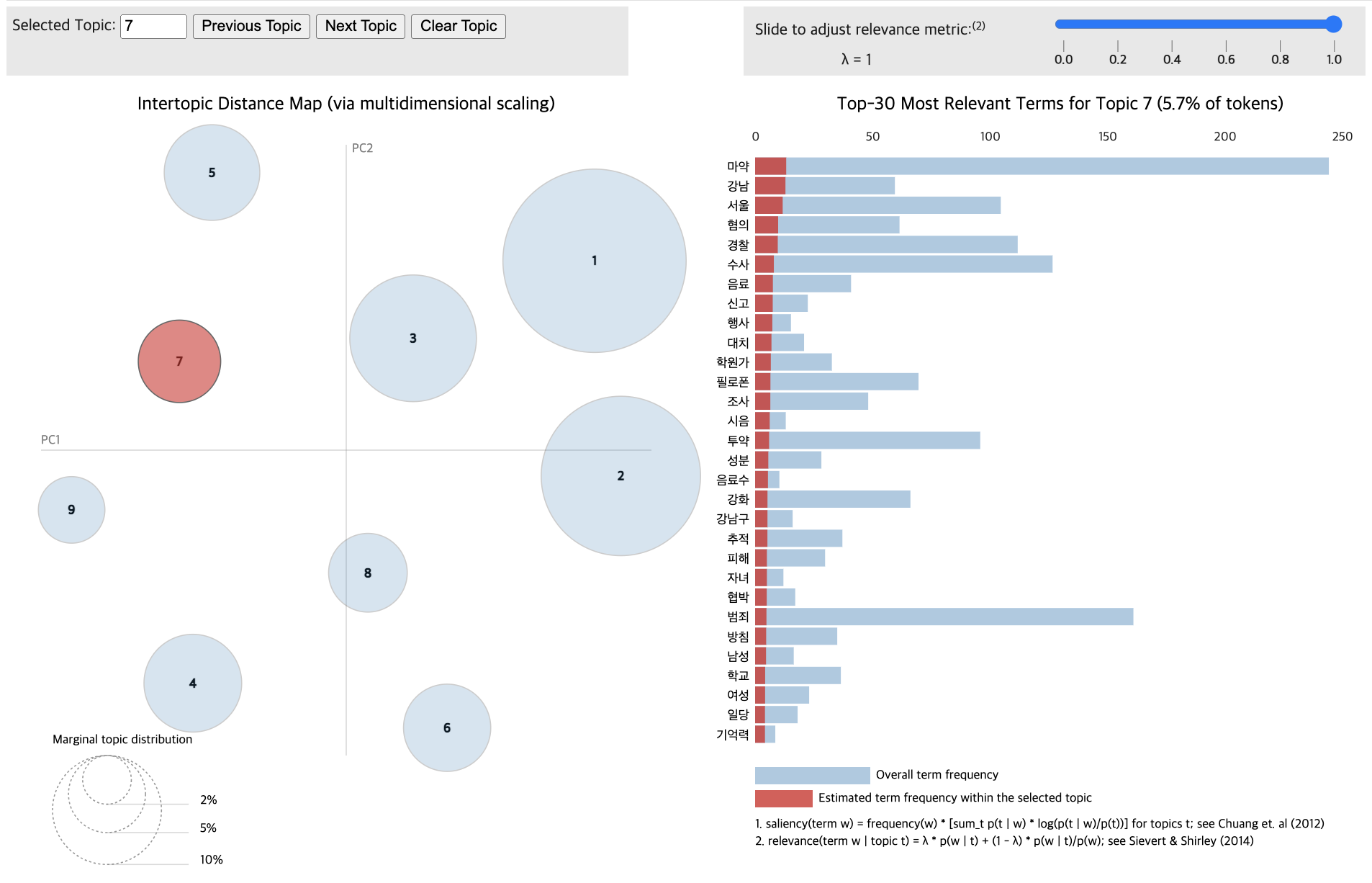

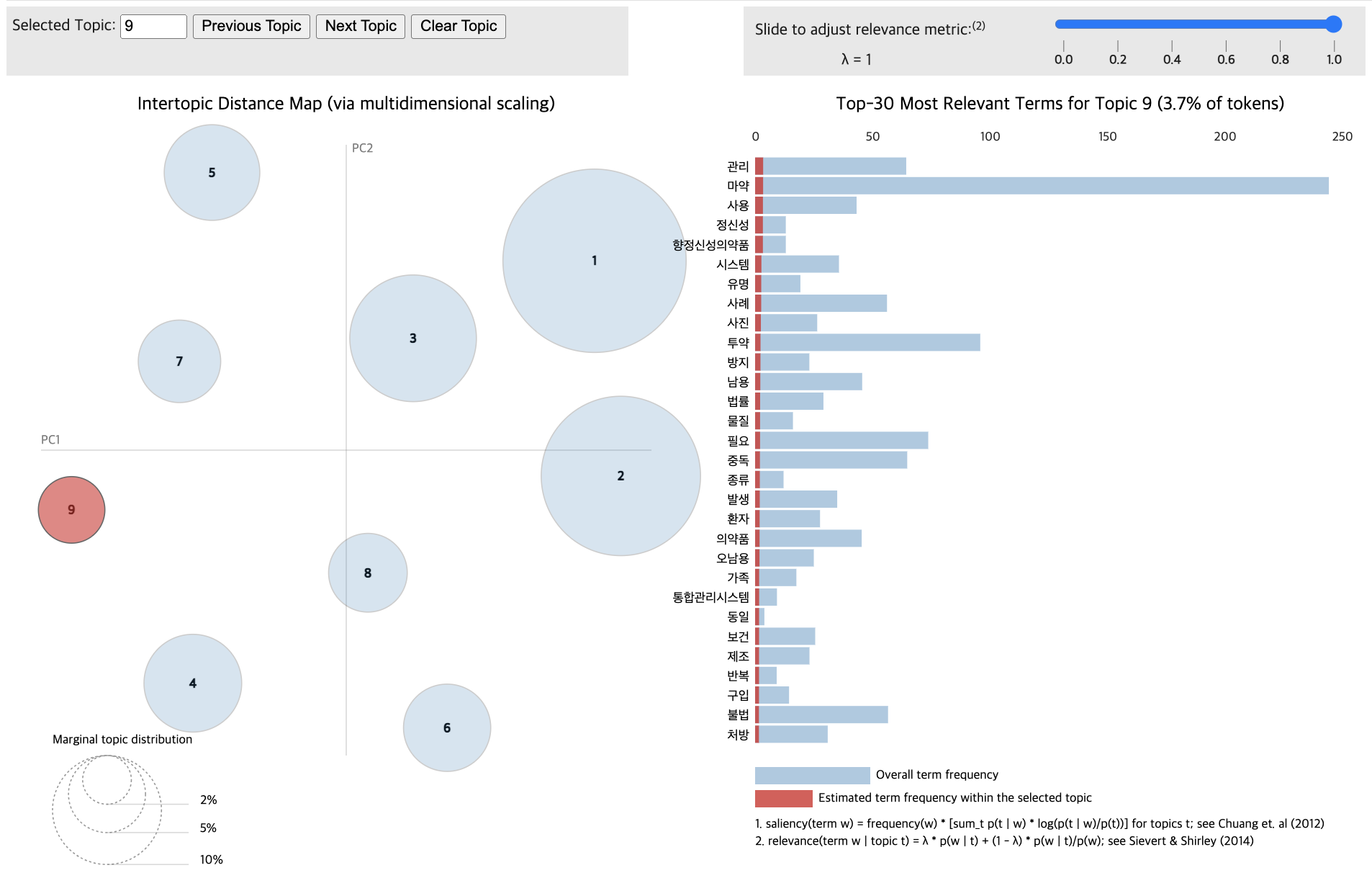
for topic in lda_data_with.print_topics(num_topics=12):
topic_num, topic_keywords = topic
print(f"{topic_num} : {topic_keywords}")1 : 0.003*"마약" + 0.003*"문제" + 0.002*"범죄" + 0.002*"국민" + 0.002*"의원" + 0.002*"민주당" + 0.002*"유지" + 0.002*"서울" + 0.002*"마약사범" + 0.002*"나라"
2 : 0.006*"마약" + 0.004*"검찰" + 0.004*"혐의" + 0.004*"서울" + 0.004*"수사" + 0.003*"중앙" + 0.003*"지검" + 0.003*"아들" + 0.003*"서울중앙지검" + 0.003*"범죄"
3 : 0.007*"마약" + 0.005*"범죄" + 0.005*"서울" + 0.005*"수사" + 0.004*"검찰" + 0.004*"밀수" + 0.004*"유통" + 0.004*"검찰청" + 0.004*"국내" + 0.003*"조직"
4 : 0.007*"마약" + 0.004*"혐의" + 0.004*"필요" + 0.004*"선고" + 0.003*"투약" + 0.003*"처벌" + 0.003*"중독" + 0.003*"치료" + 0.003*"범죄" + 0.003*"약물"
5 : 0.006*"마약" + 0.004*"거래" + 0.004*"범죄" + 0.004*"경찰" + 0.004*"중독" + 0.003*"투약" + 0.003*"판매" + 0.003*"마약사범" + 0.003*"청소년" + 0.003*"서비스"
6 : 0.003*"멕시코" + 0.003*"미국" + 0.003*"마약" + 0.003*"카르텔" + 0.003*"대통령" + 0.003*"밀매" + 0.002*"작전" + 0.002*"중국" + 0.002*"로페스" + 0.002*"드레스"
7 : 0.006*"마약" + 0.006*"범죄" + 0.005*"수사" + 0.005*"정부" + 0.004*"마약범죄" + 0.004*"마약사범" + 0.004*"서울" + 0.004*"기관" + 0.004*"검찰" + 0.004*"투약"
8 : 0.009*"강남" + 0.008*"마약" + 0.007*"경찰" + 0.007*"서울" + 0.006*"범죄" + 0.006*"수사" + 0.005*"음료" + 0.005*"경찰청" + 0.005*"검거" + 0.005*"학원가"9 : 0.006*"마약" + 0.004*"범죄" + 0.004*"정부" + 0.004*"수사" + 0.004*"대응" + 0.004*"필요" + 0.003*"서울" + 0.003*"국가" + 0.003*"조직" + 0.003*"통폐합"10 : 0.004*"마약" + 0.004*"참사" + 0.004*"이태원" + 0.003*"국민" + 0.003*"국회" + 0.003*"국정" + 0.003*"위원회" + 0.003*"규명" + 0.003*"국정조사" + 0.003*"의원"11 : 0.005*"마약" + 0.005*"수사" + 0.004*"범죄" + 0.003*"검찰" + 0.003*"정부" + 0.003*"국가" + 0.003*"전쟁" + 0.003*"서울" + 0.003*"검찰청" + 0.003*"법무부"
pyLDAvis.display(vis_data_with)
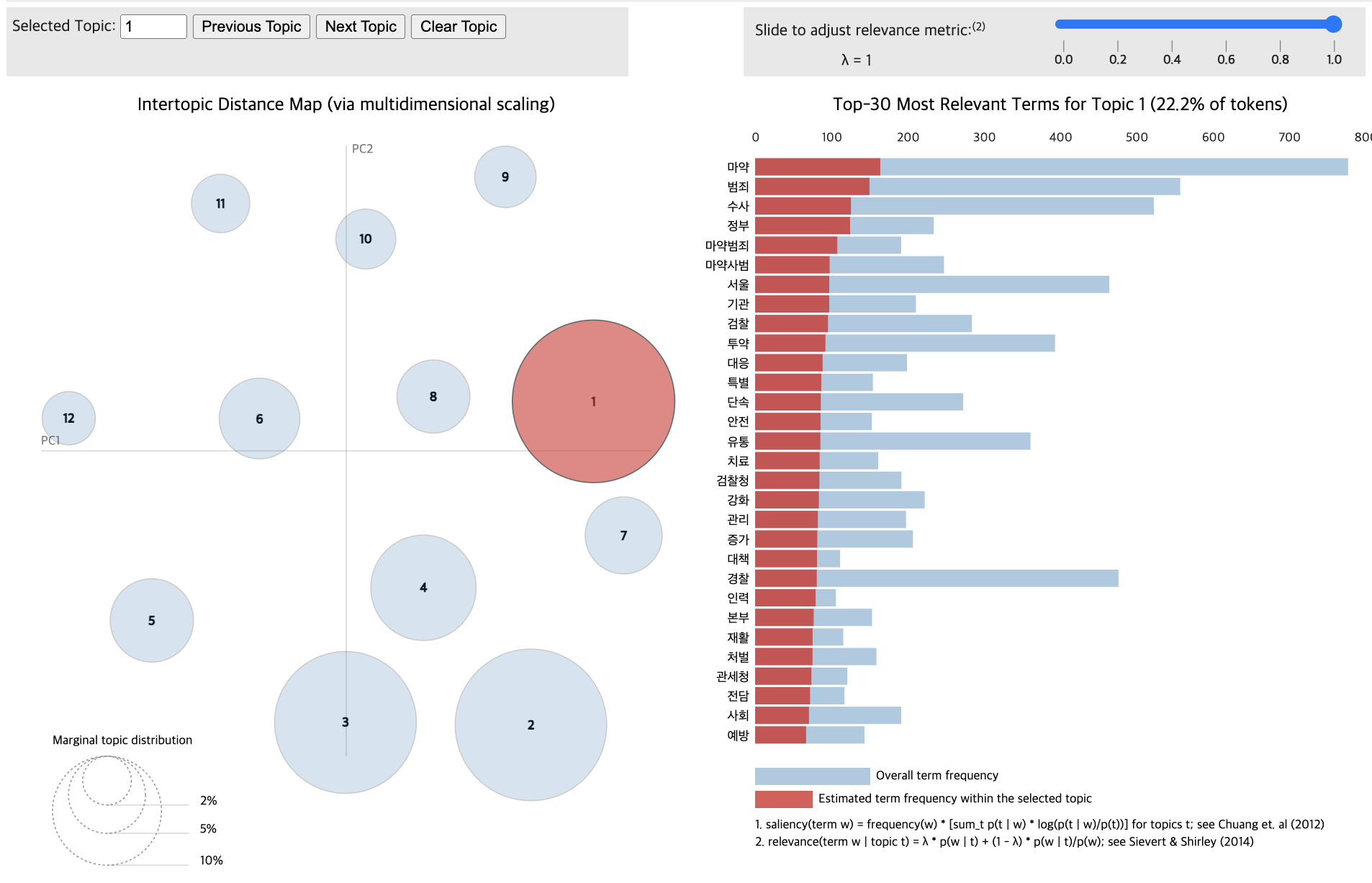

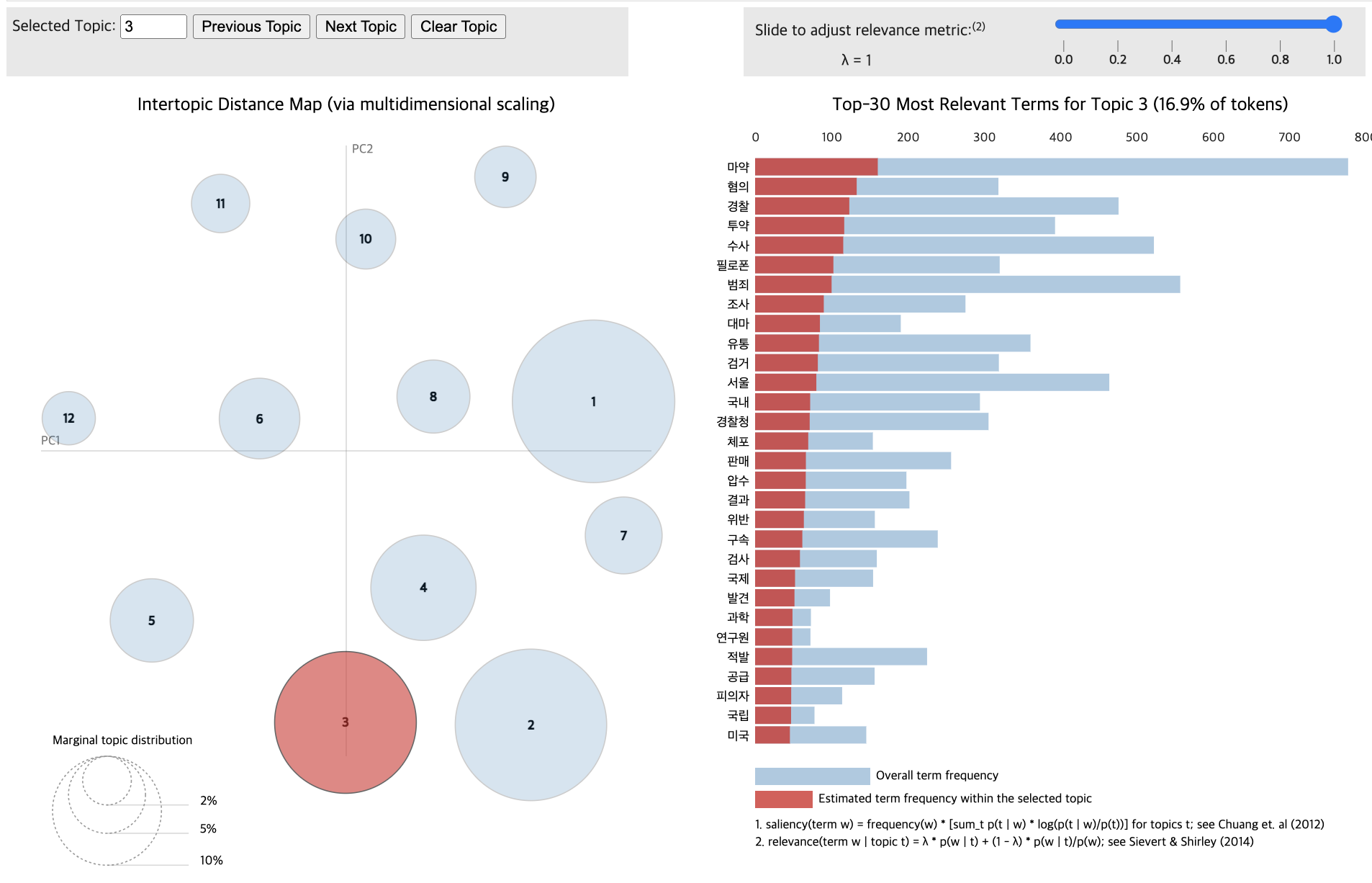
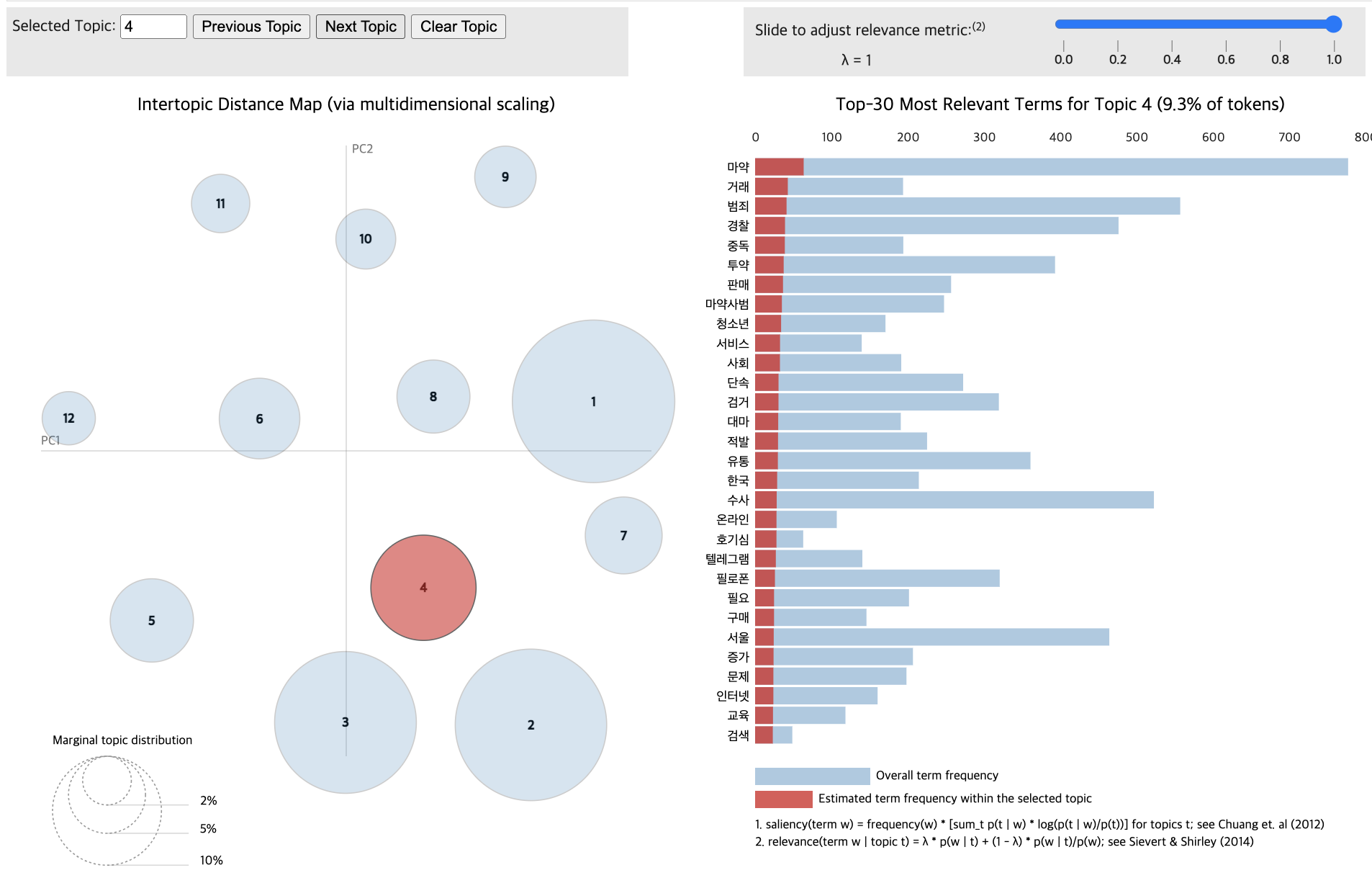
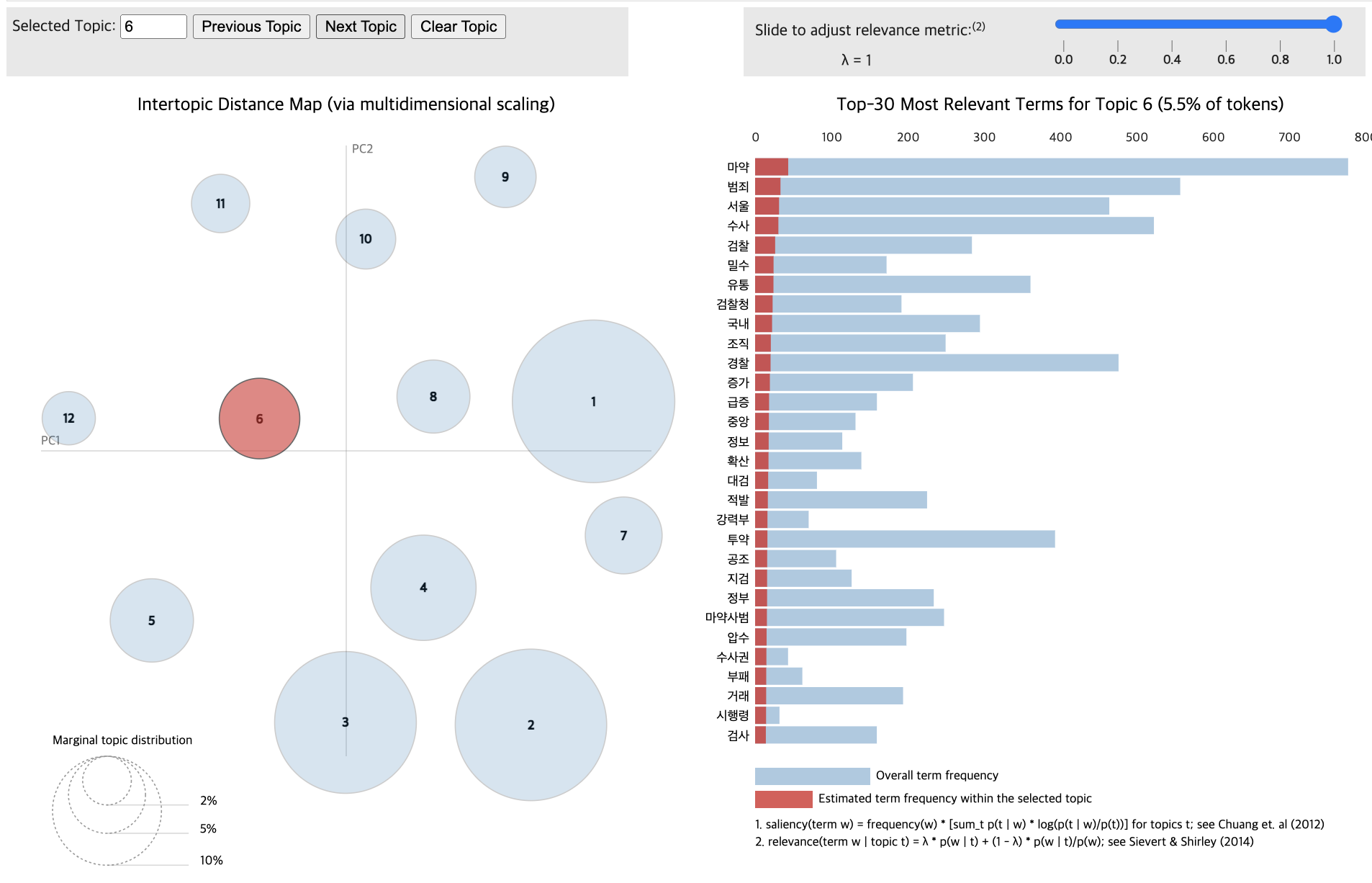
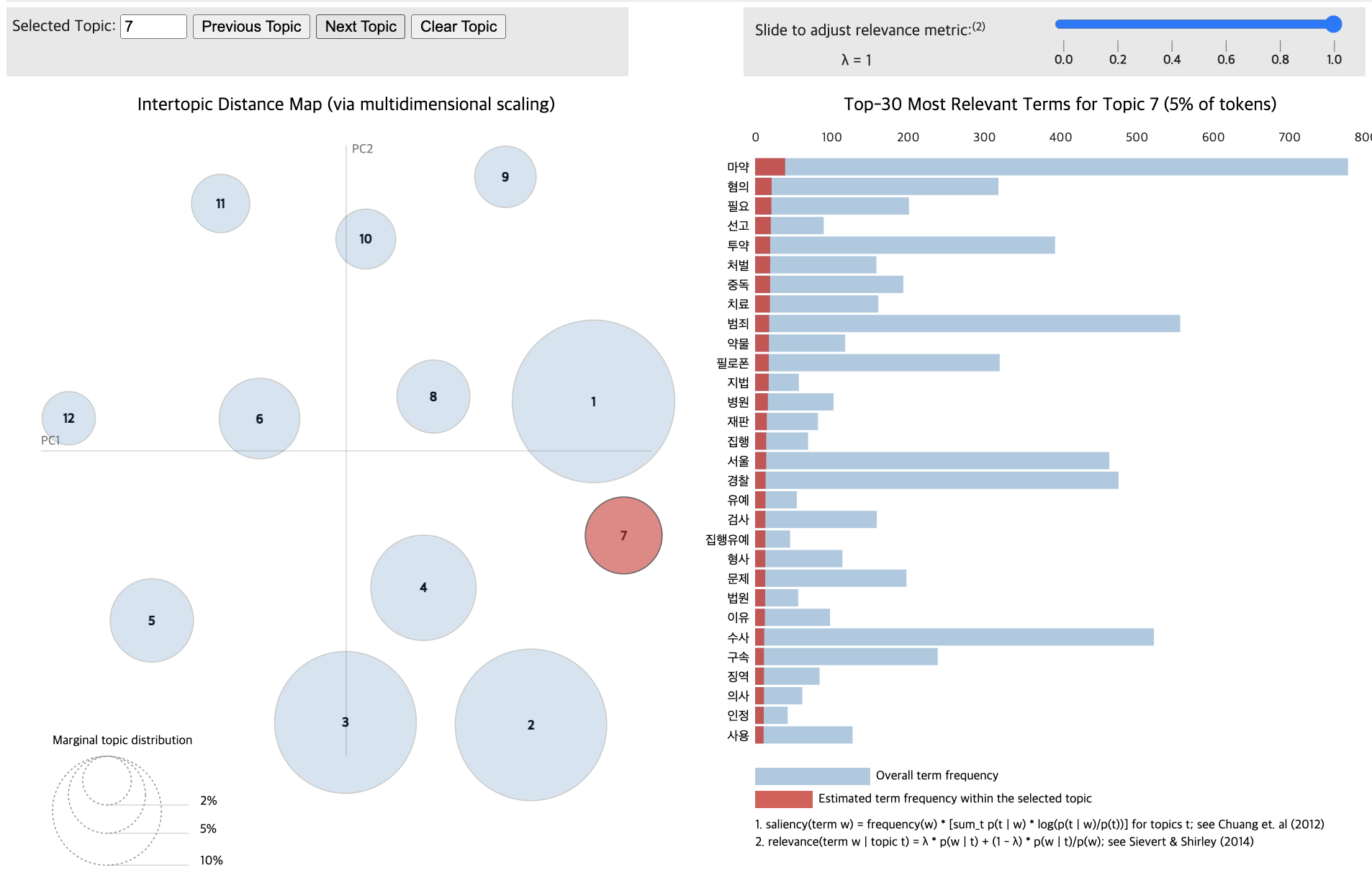
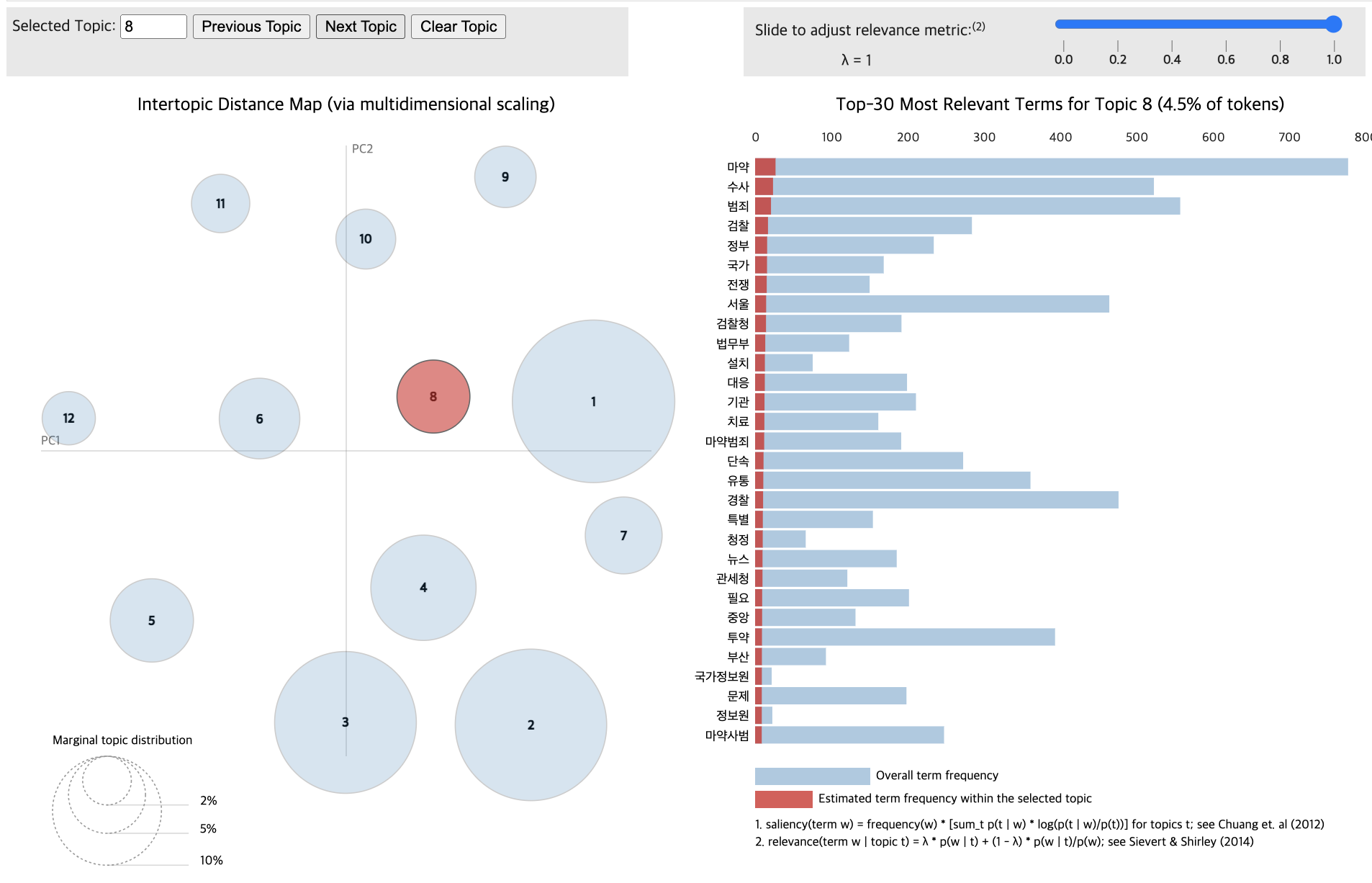
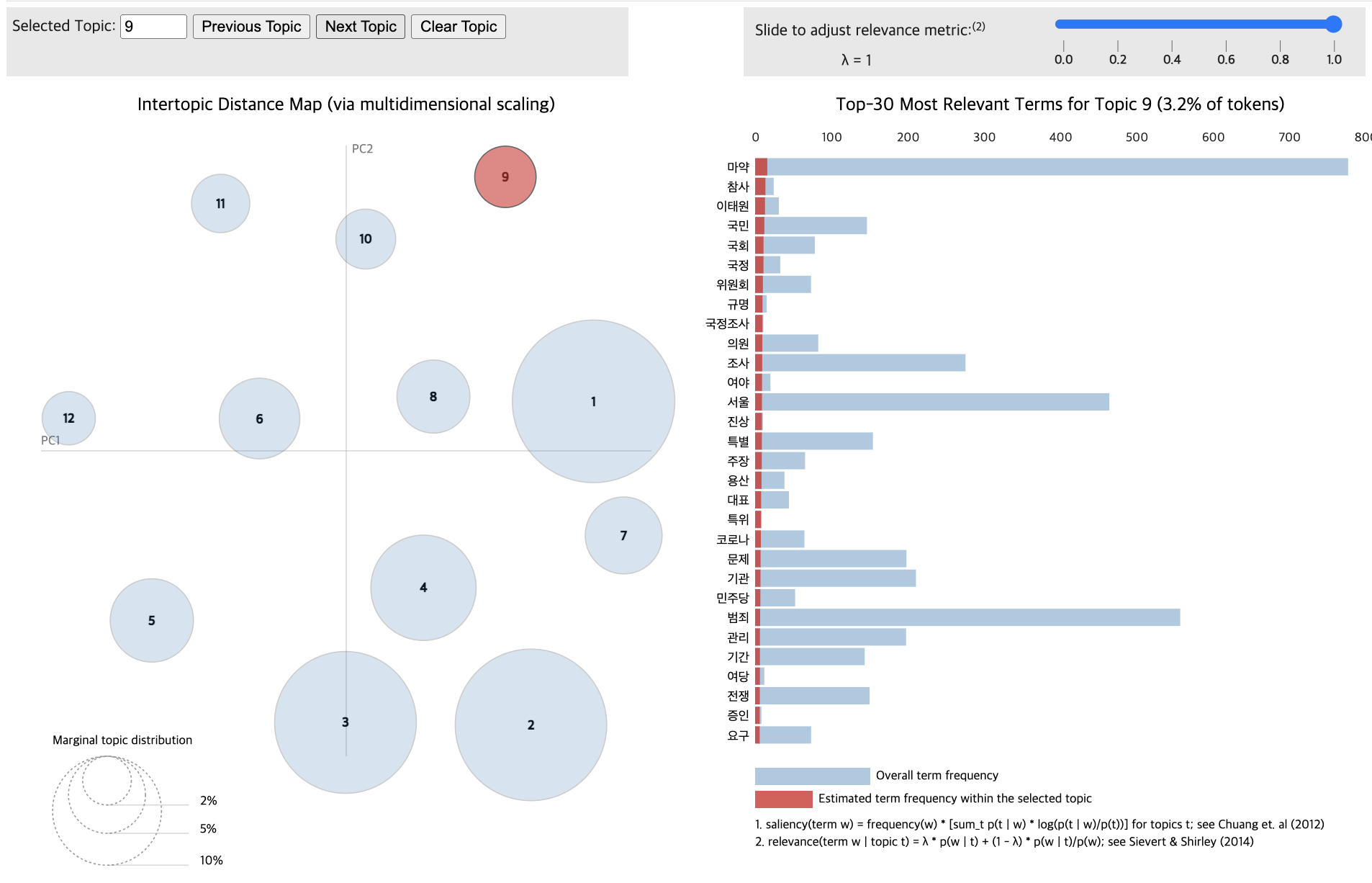
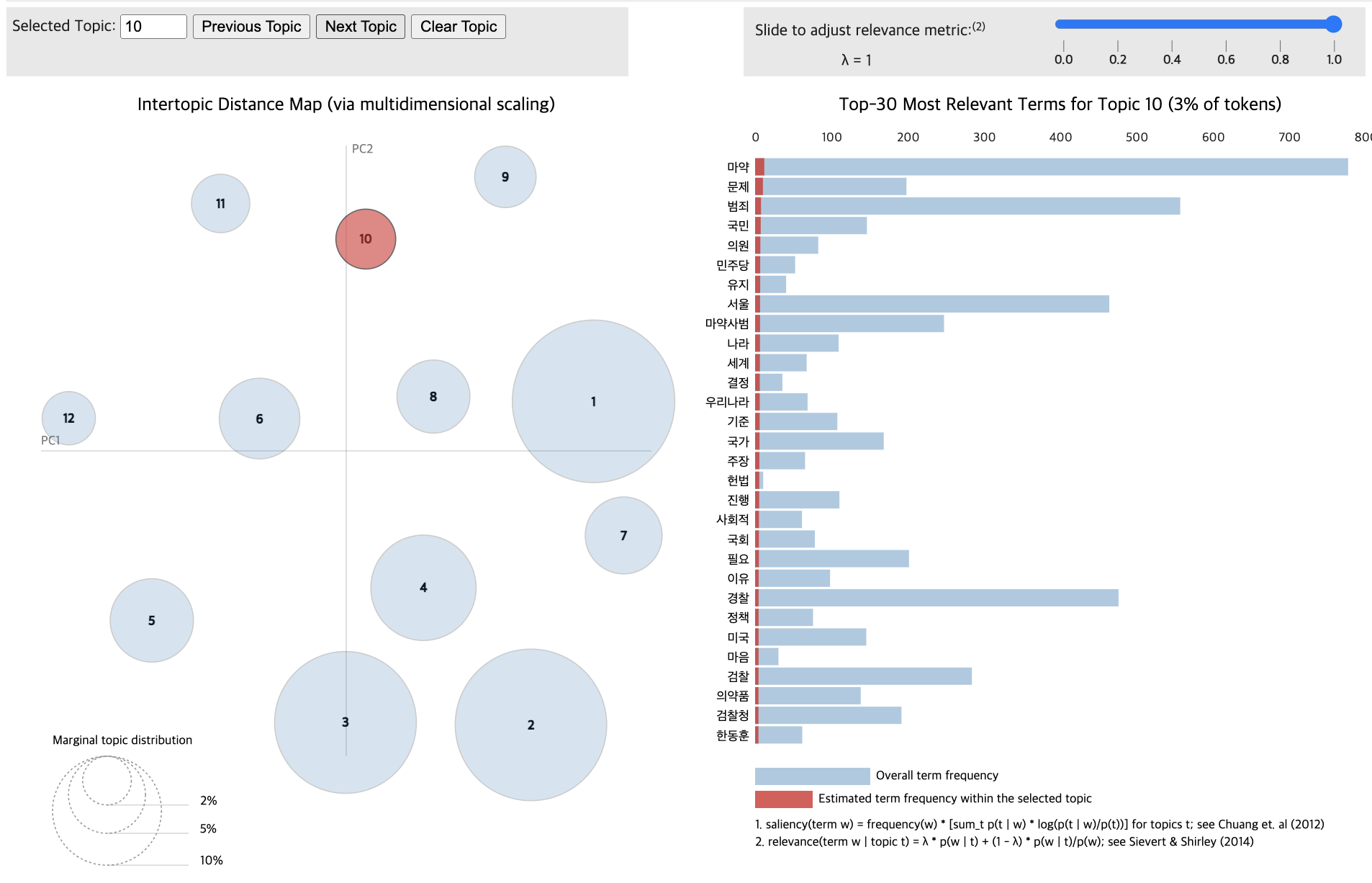
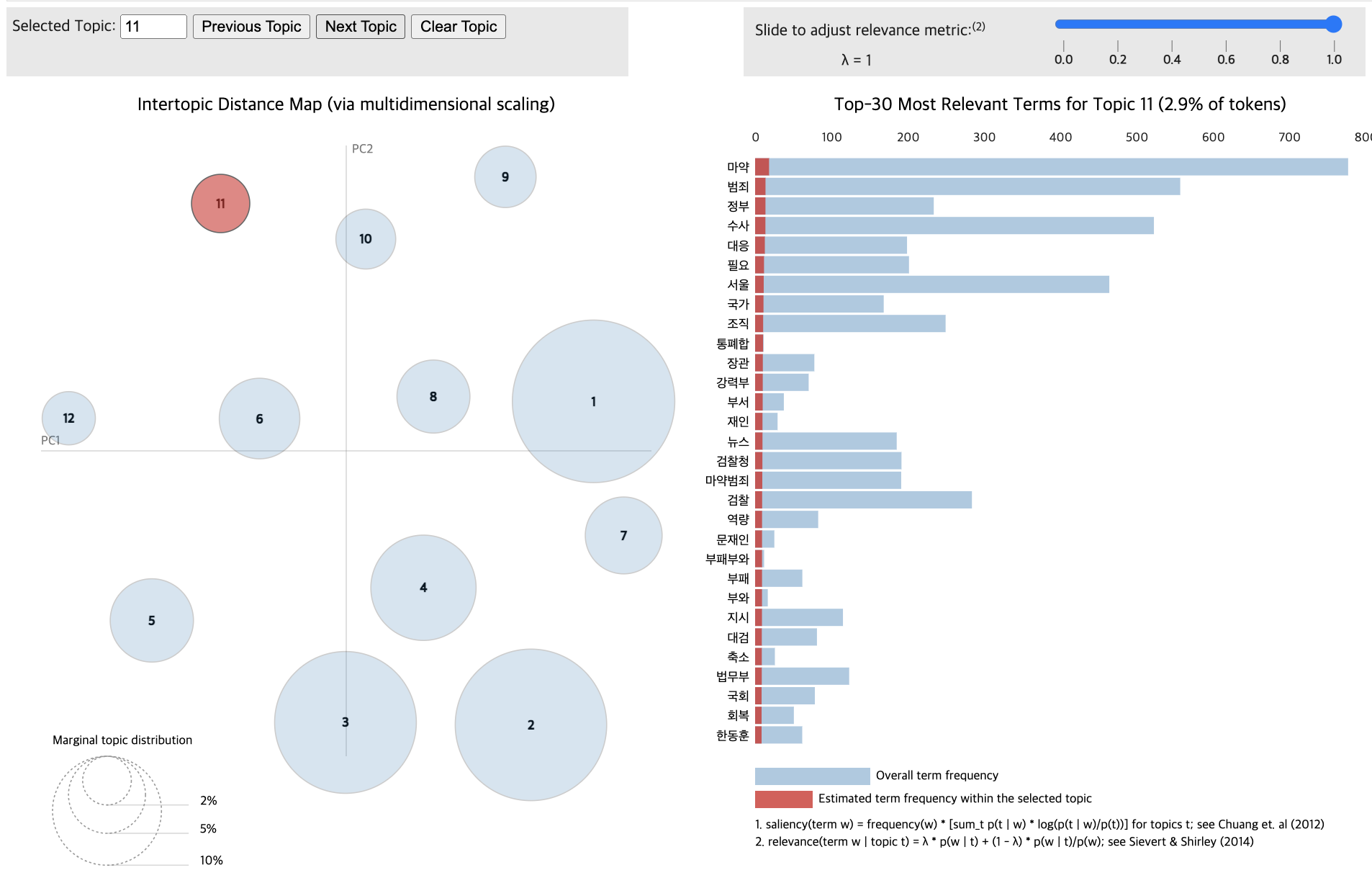
import pandas as pd
from gensim.corpora import Dictionary
from gensim.models import TfidfModel
import numpy as np
# Merge the two dictionaries
merged_dictionary = Dictionary(documents=data_without['processed'].tolist() + data_with['processed'].tolist())
# Convert the original corpora to the merged dictionary
corpus_data_without_merged = [merged_dictionary.doc2bow(doc) for doc in data_without['processed']]
corpus_data_with_merged = [merged_dictionary.doc2bow(doc) for doc in data_with['processed']]
# Update the TfidfModels
tfidf_data_without = TfidfModel(corpus_data_without_merged)
tfidf_data_with = TfidfModel(corpus_data_with_merged)
# Convert the corpus to a TF-IDF representation
corpus_tfidf_data_without_merged = tfidf_data_without[corpus_data_without_merged]
corpus_tfidf_data_with_merged = tfidf_data_with[corpus_data_with_merged]
# Calculate the average TF-IDF scores for each term in the given corpus
def calculate_avg_tfidf(tfidf_corpus, dictionary):
avg_tfidf = np.zeros(len(dictionary))
for doc in tfidf_corpus:
for term_id, tfidf_score in doc:
avg_tfidf[term_id] += tfidf_score
avg_tfidf /= len(tfidf_corpus)
return avg_tfidf
# Calculate average TF-IDF scores for each dataset
avg_tfidf_data_without = calculate_avg_tfidf(corpus_tfidf_data_without_merged, merged_dictionary)
avg_tfidf_data_with = calculate_avg_tfidf(corpus_tfidf_data_with_merged, merged_dictionary)
# Calculate the difference in average TF-IDF scores between the two datasets
tfidf_diff = avg_tfidf_data_with - avg_tfidf_data_without
# Sort the terms based on the difference in their average scores (higher in data_with)
sorted_indices = np.argsort(tfidf_diff)[::-1]
# Print the terms with their average TF-IDF scores in both groups and their difference
print(f"{'Term':<40}{'Group A':<10}{'Group B':<10}{'Difference':<10}")
print("-" * 50)
for i in sorted_indices[:40]: # Display the top 40 terms
term = merged_dictionary[i]
group_a_score = avg_tfidf_data_without[i]
group_b_score = avg_tfidf_data_with[i]
diff = tfidf_diff[i]
print(f"{term:<40}{group_a_score:<10.4f}{group_b_score:<10.4f}{diff:<10.4f}")--------------------------------------------------
상대 0.0022 0.0062 0.0040
그래픽 0.0003 0.0033 0.0030
범행 0.0050 0.0079 0.0029
정밀 0.0004 0.0033 0.0029
모발 0.0005 0.0033 0.0028
마약범죄수사대 0.0036 0.0064 0.0028
축소 0.0000 0.0027 0.0027
국립과학수사연구원 0.0017 0.0043 0.0026
유학생 0.0000 0.0026 0.0026
증거 0.0011 0.0037 0.0025
간이 0.0020 0.0045 0.0025
자택 0.0015 0.0039 0.0025
피의자 0.0045 0.0070 0.0025
가담 0.0026 0.0051 0.0025
착수 0.0025 0.0049 0.0024
아르바이트 0.0016 0.0040 0.0024
용산 0.0020 0.0044 0.0024
진술 0.0034 0.0058 0.0024
인물 0.0011 0.0035 0.0024
수색 0.0020 0.0044 0.0024
감정 0.0013 0.0036 0.0024
지시 0.0047 0.0071 0.0023
소변 0.0011 0.0034 0.0023
한동훈 0.0030 0.0053 0.0023
용의자 0.0017 0.0040 0.0023
파티 0.0017 0.0039 0.0023
의혹 0.0007 0.0029 0.0022
던지기 0.0037 0.0059 0.0022
구속영장 0.0022 0.0044 0.0022
연구원 0.0029 0.0051 0.0022
공개 0.0031 0.0053 0.0022
이모씨 0.0000 0.0022 0.0022
인근 0.0045 0.0067 0.0022
성격 0.0000 0.0022 0.0022
가능성 0.0045 0.0066 0.0022
반응 0.0032 0.0053 0.0021
주소 0.0000 0.0021 0.0021
증세 0.0007 0.0028 0.0021
파티룸 0.0000 0.0021 0.0021
영장 0.0042 0.0063 0.0021
import pandas as pd
import numpy as np
from gensim.models import Word2Vec
# Combine the preprocessed text from both groups
combined_text = data_without['processed'].tolist() + data_with['processed'].tolist()
# Train a Word2Vec model using both datasets
model = Word2Vec(sentences=combined_text, vector_size=100, window=5, min_count=1, workers=4)
# Calculate the average word embeddings for each article in both groups
def average_word_embeddings(text, word2vec_model):
embeddings = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]
if embeddings:
return np.mean(embeddings, axis=0)
else:
return np.zeros(word2vec_model.vector_size)
data_without['avg_word_embeddings'] = data_without['processed'].apply(average_word_embeddings, word2vec_model=model)
data_with['avg_word_embeddings'] = data_with['processed'].apply(average_word_embeddings, word2vec_model=model)
# Calculate the average word embeddings for both groups
group_a_avg = np.mean(np.vstack(data_without['avg_word_embeddings']), axis=0)
group_b_avg = np.mean(np.vstack(data_with['avg_word_embeddings']), axis=0)
# Get all unique keywords from both groups
keywords = set()
for text in combined_text:
keywords.update(text)
keywords = list(keywords)
keyword_vectors = np.vstack([model.wv[keyword] for keyword in keywords])
# Calculate the similarity scores between the keywords and the average word embeddings for both groups
keyword_scores_a = np.dot(keyword_vectors, group_a_avg)
keyword_scores_b = np.dot(keyword_vectors, group_b_avg)
# Calculate the difference in similarity scores between the two groups for each keyword
keyword_diffs = keyword_scores_b - keyword_scores_a
# Sort the keywords based on the difference in their embeddings (higher in data_with)
sorted_indices = np.argsort(keyword_diffs)[::-1]
# Print the keywords with their similarity scores in both groups and their difference
print(f"{'Term':<40}{'Group A':<10}{'Group B':<10}{'Difference':<10}")
print("-" * 50)
count = 0
for i in sorted_indices:
if count >= 40: # Display the top 20 terms
break
term = keywords[i]
group_a_score = keyword_scores_a[i]
group_b_score = keyword_scores_b[i]
diff = keyword_diffs[i]
print(f"{term:<40}{group_a_score:<10.4f}{group_b_score:<10.4f}{diff:<10.4f}")
count += 1--------------------------------------------------
원경찰서 0.0865 0.0886 0.0021
개발됐다 -0.0012 -0.0005 0.0008
의심경찰 -0.0045 -0.0038 0.0007
서울교육청 -0.0421 -0.0415 0.0005
잠시 -0.0510 -0.0505 0.0005
제공올해 -0.0322 -0.0317 0.0005
혐의경찰 0.0487 0.0492 0.0005
제공국내 -0.0448 -0.0443 0.0005
확인경찰 0.0095 0.0099 0.0004
제공부산경찰청 -0.0286 -0.0282 0.0004
기소대 -0.0106 -0.0102 0.0004
구속기소범죄단체 -0.0091 -0.0087 0.0004
구속거래 0.0624 0.0628 0.0004
서울중앙지검검찰 0.0145 0.0148 0.0004
유통현지 -0.0295 -0.0291 0.0003
귀가조치텔레 -0.0083 -0.0080 0.0003
냉장고 0.0478 0.0481 0.0003
중국내 -0.0291 -0.0288 0.0003
월부 0.0229 0.0232 0.0003
제공경남경찰청 0.0390 0.0393 0.0003
체포마약 0.0520 0.0523 0.0003
회의년 -0.0187 -0.0184 0.0003
신고해경찰 0.0481 0.0484 0.0003
잠잠 -0.0063 -0.0061 0.0002
지적마약 -0.0335 -0.0333 0.0002
뉴스올해 0.0537 0.0540 0.0002
강화내년 -0.0041 -0.0039 0.0002
묵묵부답 0.0572 0.0575 0.0002
구성경찰 0.0493 0.0495 0.0002
전년비 -0.0107 -0.0105 0.0002
경남경찰 0.0044 0.0046 0.0002
진술경찰 0.0125 0.0127 0.0002
제공윗 0.0263 0.0265 0.0002
부산지방검찰청 -0.0263 -0.0261 0.0002
검찰청검찰 -0.0058 -0.0056 0.0002
차도 0.0355 0.0357 0.0002
총동원키 -0.0113 -0.0111 0.0002
중간브리핑현재 0.0845 0.0846 0.0002
급등 -0.0152 -0.0151 0.0002
도심인 0.0552 0.0553 0.0002
import pandas as pd
# Load the modified data
data = pd.read_csv("final_combined.csv")
# Remove commas from the comment_count column
# data['comment_count'] = data['comment_count'].str.replace(',', '')
# Convert the comment_count column to floats
data['comment_count'] = data['comment_count'].astype(float)
# Fill missing values with 0
data['comment_count'].fillna(0, inplace=True)
# Convert the comment_count column to integers
data['comment_count'] = data['comment_count'].astype(int)
data_without = data[(data['comment_count'] >= 1) & (data['comment_count'] < 10)]
data_with = data[data['comment_count'] >= 10]
# Save the classified data to separate CSV files
data_without.to_csv("data_without_comments.csv", index=False)
data_with.to_csv("data_with_comments.csv", index=False)print(len(data_without))
print(len(data_with))485
import pandas as pd
from gensim.corpora import Dictionary
from gensim.models import LdaModel
import pyLDAvis.gensim_models as gensimvis
import pyLDAvis
import matplotlib.pyplot as plt
from gensim.models.coherencemodel import CoherenceModel
import re
# Read the CSV files
data_without = pd.read_csv("data_without_comments.csv")
data_with = pd.read_csv("data_with_comments.csv")
# Text cleaning function: Remove all non-Korean characters
def text_cleaning(text):
# Extract only Korean text using Korean regular expression
hangul = re.compile('[^ ㄱ-ㅣ가-힣]+')
result = hangul.sub('', text)
return result
def split_text(text):
tokens = text.split()
return tokens
# Check the processed text after applying text cleaning
data_without['content_cleaned'] = data_without['content_tokenized'].apply(text_cleaning)
data_with['content_cleaned'] = data_with['content_tokenized'].apply(text_cleaning)
data_without['processed'] = data_without['content_cleaned'].apply(split_text)
data_with['processed'] = data_with['content_cleaned'].apply(split_text)
# Create the dictionary and corpus for each dataset
dictionary_data_without = Dictionary(data_without['processed'])
dictionary_data_with = Dictionary(data_with['processed'])
corpus_data_without = [dictionary_data_without.doc2bow(doc) for doc in data_without['processed']]
corpus_data_with = [dictionary_data_with.doc2bow(doc) for doc in data_with['processed']]
# Set topic range
topic_range = range(4, 20, 1)
# Compute perplexity
def compute_perplexity(dictionary, corpus, num_topics):
model = LdaModel(corpus=corpus, num_topics=num_topics, id2word=dictionary, passes=20, random_state=42)
return model.log_perplexity(corpus)
# Compute coherence score
def compute_coherence_score(dictionary, corpus, tokens, num_topics):
model = LdaModel(corpus=corpus, num_topics=num_topics, id2word=dictionary, passes=20, random_state=42)
coherence_model = CoherenceModel(model=model, texts=tokens, dictionary=dictionary, coherence='c_v')
return coherence_model.get_coherence()
# Calculate scores while displaying progress
def calculate_scores(num_topics, dictionary, corpus, tokens):
perplexity = compute_perplexity(dictionary, corpus, num_topics)
coherence = compute_coherence_score(dictionary, corpus, tokens, num_topics)
print(f"Completed: {num_topics} Topics - Perplexity: {perplexity}, Coherence: {coherence}")
return perplexity, coherence
# Calculate and plot scores for each dataset
for dataset_name, dictionary, corpus, tokens, xlabel in [('data_without', dictionary_data_without, corpus_data_without, data_without['processed'], "Group A(1 ~ 9 comments)"),
('data_with', dictionary_data_with, corpus_data_with, data_with['processed'], "Group B(10 or more comments)")]:
# Calculate scores within the topic range
scores = [calculate_scores(num_topics, dictionary, corpus, tokens) for num_topics in topic_range]
# Separate results
perplexity_scores, coherence_scores = zip(*scores)
# Plot the graph
fig, ax1 = plt.subplots()
ax1.set_title(dataset_name)
ax1.set_xlabel(xlabel)
ax1.set_ylabel("Perplexity", color="tab:red")
ax1.plot(topic_range, perplexity_scores, color="tab:red")
ax1.tick_params(axis="y", labelcolor="tab:red")
ax2 = ax1.twinx()
ax2.set_ylabel("Coherence Score", color="tab:blue")
ax2.plot(topic_range, coherence_scores, color="tab:blue")
ax2.tick_params(axis="y", labelcolor="tab:blue")
fig.tight_layout()
plt.show()Completed: 5 Topics - Perplexity: -8.63803983912795, Coherence: 0.4632740267200511
Completed: 6 Topics - Perplexity: -8.656937817089489, Coherence: 0.47082093672198594
Completed: 7 Topics - Perplexity: -8.670857837121114, Coherence: 0.4547579558857177
Completed: 8 Topics - Perplexity: -8.690217682811348, Coherence: 0.4436930631724806
Completed: 9 Topics - Perplexity: -8.698464219032333, Coherence: 0.446931708090031
Completed: 10 Topics - Perplexity: -8.724094758470695, Coherence: 0.47454961411638513
Completed: 11 Topics - Perplexity: -8.74352544292002, Coherence: 0.45429670025215785
Completed: 12 Topics - Perplexity: -8.770439060205096, Coherence: 0.5147956085258223
Completed: 13 Topics - Perplexity: -8.789589485715892, Coherence: 0.47795116277619304
Completed: 14 Topics - Perplexity: -8.813613172271717, Coherence: 0.4638806829699484
Completed: 15 Topics - Perplexity: -8.828612113350776, Coherence: 0.5103964962448824
Completed: 16 Topics - Perplexity: -8.86026715907384, Coherence: 0.4693816598070335
Completed: 17 Topics - Perplexity: -8.851621362046373, Coherence: 0.4689641452453423
Completed: 18 Topics - Perplexity: -8.857703061006223, Coherence: 0.4679362152353526
Completed: 19 Topics - Perplexity: -8.849652710500655, Coherence: 0.46518562567329186
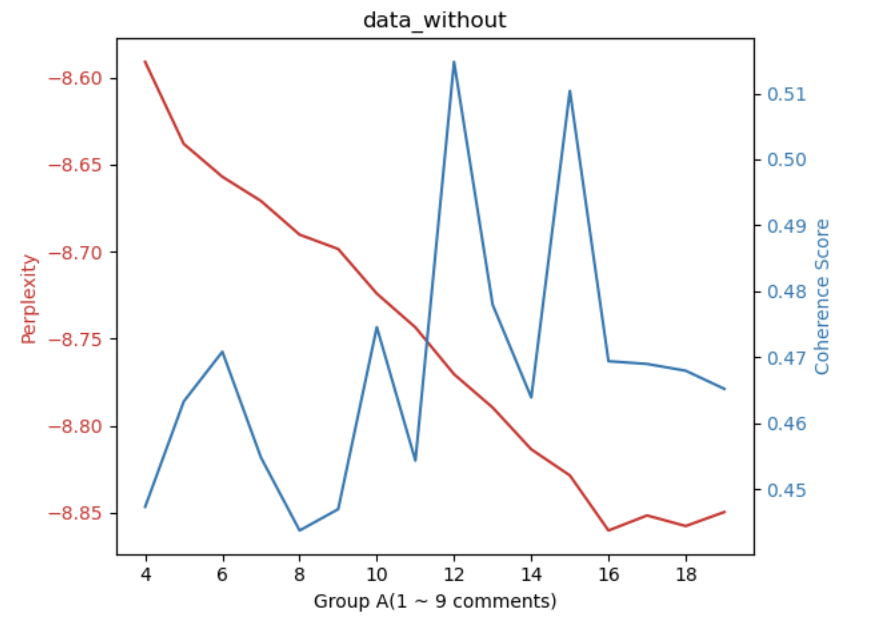
Completed: 5 Topics - Perplexity: -8.547553802114498, Coherence: 0.5061324846289026
Completed: 6 Topics - Perplexity: -8.56481048022909, Coherence: 0.5430187560602211
Completed: 7 Topics - Perplexity: -8.578409012000286, Coherence: 0.47527999033650786
Completed: 8 Topics - Perplexity: -8.601173144618382, Coherence: 0.5139339415356374
Completed: 9 Topics - Perplexity: -8.605053921091281, Coherence: 0.524073970290125
Completed: 10 Topics - Perplexity: -8.614856219950422, Coherence: 0.5185326108449447
Completed: 11 Topics - Perplexity: -8.628124133596275, Coherence: 0.5297326551148344
Completed: 12 Topics - Perplexity: -8.631644243923503, Coherence: 0.5016333769346382
Completed: 13 Topics - Perplexity: -8.642250431255997, Coherence: 0.5037746071392994
Completed: 14 Topics - Perplexity: -8.656054606151375, Coherence: 0.4724603441184766
Completed: 15 Topics - Perplexity: -8.671224001587772, Coherence: 0.4950675653532071
Completed: 16 Topics - Perplexity: -8.688725515297275, Coherence: 0.46957102441331877
Completed: 17 Topics - Perplexity: -8.710010236770225, Coherence: 0.4695878652019895
Completed: 18 Topics - Perplexity: -8.710020177949511, Coherence: 0.4655527534944102
Completed: 19 Topics - Perplexity: -8.70840365303902, Coherence: 0.4947996585860993

Based on complexity and cohesion calculations (20 passes, random state 42), 12 topics were determined optimal for both Group A and Group B.
# Train the LDA models
lda_data_without = LdaModel(corpus_data_without, id2word=dictionary_data_without, num_topics=12, passes=20, random_state=42)
lda_data_with = LdaModel(corpus_data_with, id2word=dictionary_data_with, num_topics=11, passes=20, random_state=42)
import pyLDAvis
import pyLDAvis.gensim_models as gensimvis
vis_data_without = gensimvis.prepare(lda_data_without, corpus_data_without, dictionary_data_without, mds='mmds', n_jobs=1)
vis_data_with = gensimvis.prepare(lda_data_with, corpus_data_with, dictionary_data_with, mds='mmds', n_jobs=1)
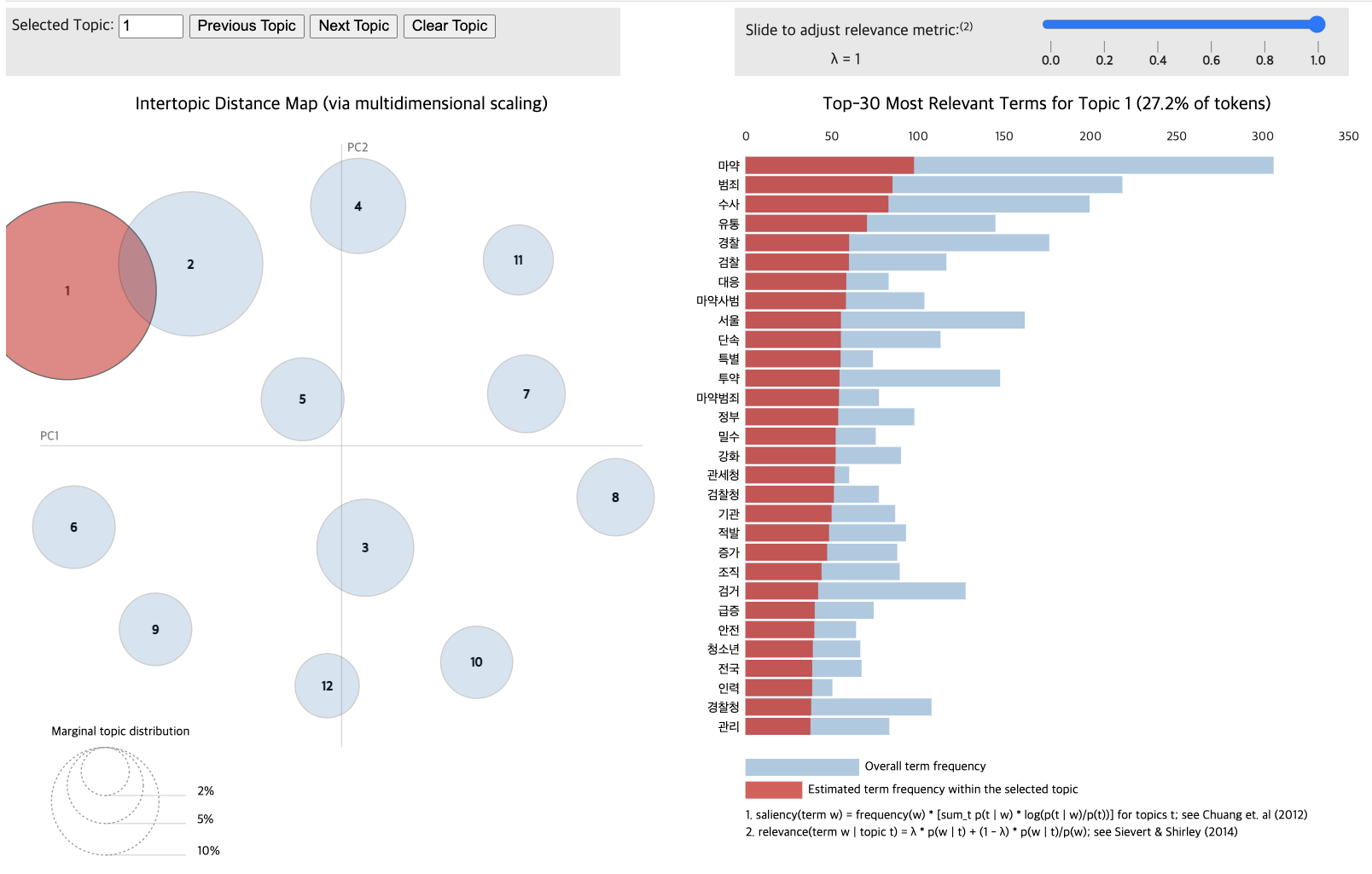
for topic in lda_data_without.print_topics(num_topics=12):
topic_num, topic_keywords = topic
print(f"{topic_num} : {topic_keywords}")1 : 0.007*"마약" + 0.006*"수사" + 0.006*"경찰" + 0.005*"범죄" + 0.005*"투약" + 0.004*"혐의" + 0.004*"서울" + 0.003*"필로폰" + 0.003*"조사" + 0.003*"경찰청"
2 : 0.008*"마약" + 0.007*"범죄" + 0.007*"수사" + 0.006*"유통" + 0.005*"경찰" + 0.005*"검찰" + 0.005*"대응" + 0.005*"마약사범" + 0.004*"서울" + 0.004*"단속"
3 : 0.005*"마약" + 0.004*"범죄" + 0.003*"정부" + 0.003*"기관" + 0.003*"예방" + 0.003*"강화" + 0.003*"한국" + 0.003*"급증" + 0.003*"중독" + 0.002*"본부"
4 : 0.004*"마약" + 0.003*"서울" + 0.003*"소스" + 0.003*"투약" + 0.003*"혐의" + 0.003*"범죄" + 0.002*"사용" + 0.002*"조사" + 0.002*"제공" + 0.002*"케타민"
5 : 0.004*"마약" + 0.003*"투약" + 0.002*"범죄" + 0.002*"조사" + 0.002*"병원" + 0.002*"문제" + 0.002*"중독" + 0.002*"필요" + 0.002*"사이" + 0.002*"한국"
6 : 0.006*"수사" + 0.006*"마약" + 0.006*"경찰" + 0.005*"범죄" + 0.005*"경찰청" + 0.004*"조직" + 0.004*"조사" + 0.004*"유통" + 0.004*"국내" + 0.004*"검거"
7 : 0.005*"마약" + 0.003*"중독" + 0.002*"남용" + 0.002*"치료" + 0.002*"범죄" + 0.002*"약물" + 0.002*"의원" + 0.002*"생산" + 0.002*"한국" + 0.002*"규제"
8 : 0.008*"마약" + 0.006*"수사" + 0.006*"경찰" + 0.005*"검거" + 0.005*"범죄" + 0.005*"투약" + 0.005*"혐의" + 0.005*"서울" + 0.005*"유통" + 0.004*"판매"
9 : 0.005*"마약" + 0.004*"혐의" + 0.004*"위반" + 0.003*"기소" + 0.003*"범죄" + 0.003*"재판" + 0.003*"단체" + 0.003*"검찰" + 0.003*"수법" + 0.003*"수사"
10 : 0.005*"마약" + 0.004*"수사" + 0.004*"범죄" + 0.003*"검찰청" + 0.003*"정부" + 0.003*"검찰" + 0.002*"지적" + 0.002*"국민" + 0.002*"국회" + 0.002*"한국"
11 : 0.007*"마약" + 0.006*"강남" + 0.005*"서울" + 0.005*"경찰" + 0.005*"혐의" + 0.005*"범죄" + 0.004*"음료" + 0.004*"학원가" + 0.003*"대치" + 0.003*"학생"
for topic in lda_data_with.print_topics(num_topics=11):
topic_num, topic_keywords = topic
print(f"{topic_num} : {topic_keywords}")1 : 0.006*"마약" + 0.006*"수사" + 0.006*"국회" + 0.005*"장관" + 0.005*"검찰" + 0.005*"법무부" + 0.005*"한동훈" + 0.004*"민주당" + 0.004*"서울" + 0.004*"축소"
2 : 0.007*"마약" + 0.006*"범죄" + 0.005*"수사" + 0.005*"유통" + 0.005*"서울" + 0.004*"검찰" + 0.004*"투약" + 0.004*"검찰청" + 0.004*"단속" + 0.004*"기관"
3 : 0.003*"부상자" + 0.003*"발생" + 0.003*"사고" + 0.002*"내용" + 0.002*"자동차" + 0.002*"가입" + 0.002*"국토" + 0.002*"국토부" + 0.002*"부상자별" + 0.002*"배상"
4 : 0.006*"마약" + 0.005*"범죄" + 0.005*"경찰" + 0.005*"투약" + 0.004*"수사" + 0.004*"검거" + 0.004*"필로폰" + 0.004*"판매" + 0.004*"유통" + 0.004*"경찰청"
5 : 0.007*"마약" + 0.004*"범죄" + 0.004*"전쟁" + 0.004*"서울" + 0.004*"마약범죄" + 0.004*"정부" + 0.003*"수사" + 0.003*"대응" + 0.003*"국가" + 0.003*"회의"
6 : 0.008*"마약" + 0.008*"강남" + 0.008*"경찰" + 0.007*"서울" + 0.007*"혐의" + 0.006*"수사" + 0.006*"범죄" + 0.005*"조사" + 0.005*"필로폰" + 0.005*"구속"
7 : 0.002*"건강" + 0.002*"문제" + 0.001*"투약" + 0.001*"중국" + 0.001*"헤로" + 0.001*"헤로인의" + 0.001*"무방비" + 0.001*"뱅크" + 0.001*"액상" + 0.001*"필요"
8 : 0.004*"미국" + 0.004*"대통령" + 0.003*"마약" + 0.003*"카르텔" + 0.003*"멕시코" + 0.002*"불법" + 0.002*"마약단속국" + 0.002*"워싱턴" + 0.002*"단속" + 0.002*"협조"
9 : 0.004*"마약" + 0.003*"범죄" + 0.003*"수사" + 0.002*"서울" + 0.002*"정부" + 0.002*"지적" + 0.002*"처음" + 0.002*"사회" + 0.002*"결과" + 0.002*"비판"
10 : 0.004*"마약" + 0.003*"중독" + 0.003*"병원" + 0.002*"사회" + 0.002*"미국" + 0.002*"치료" + 0.002*"모습" + 0.002*"사망" + 0.002*"안전" + 0.002*"한국"
pyLDAvis.display(vis_data_without)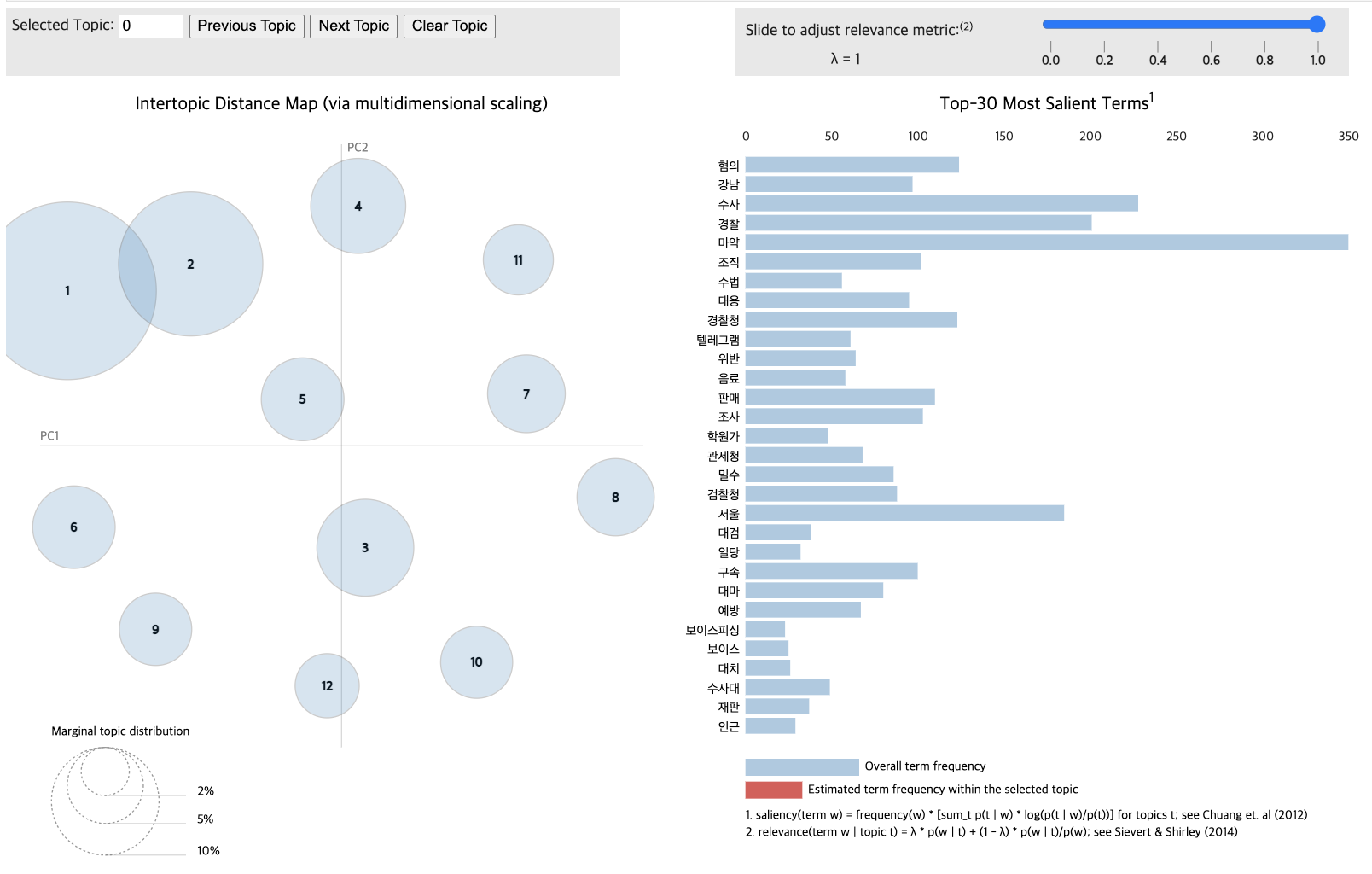
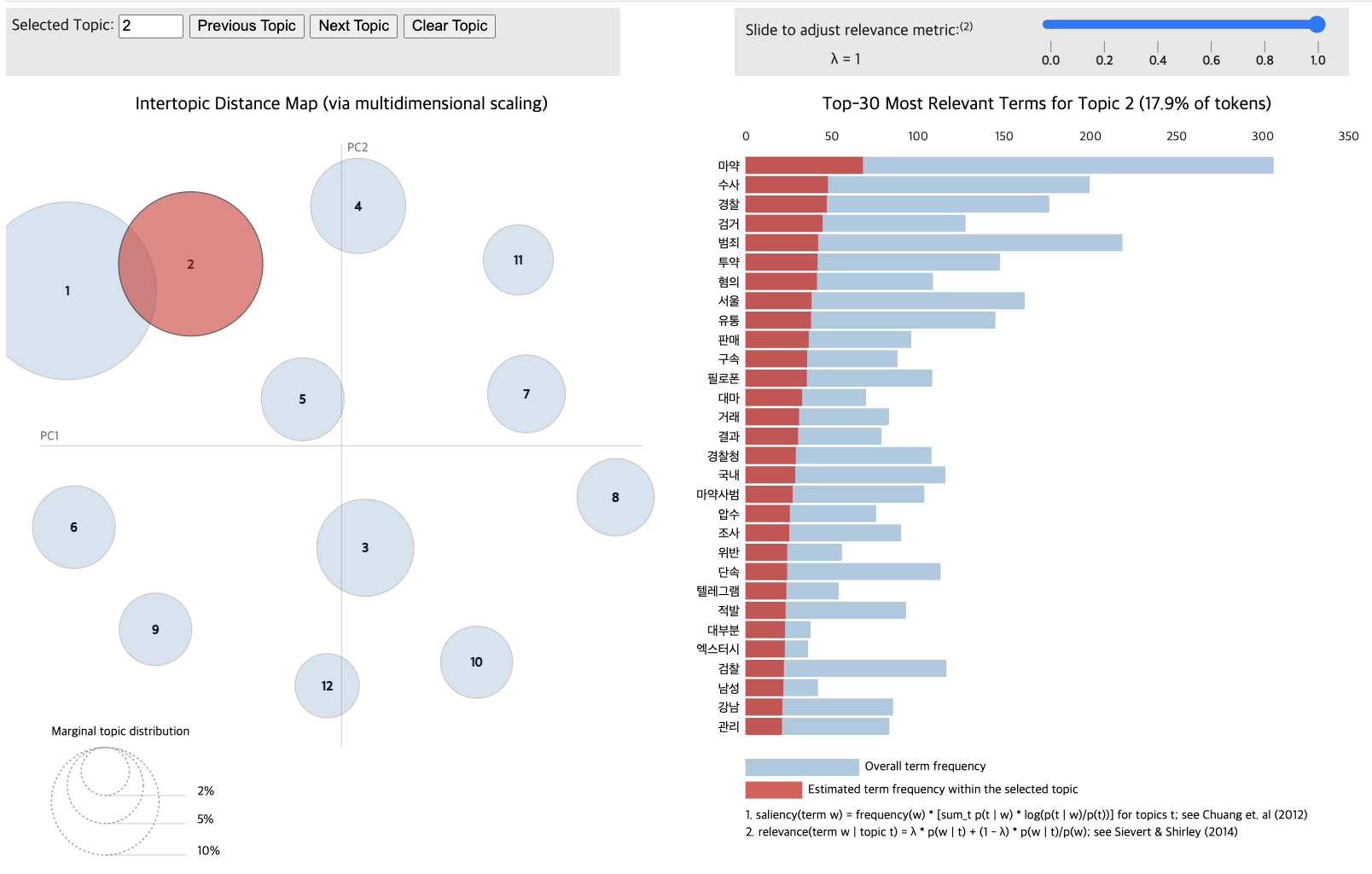
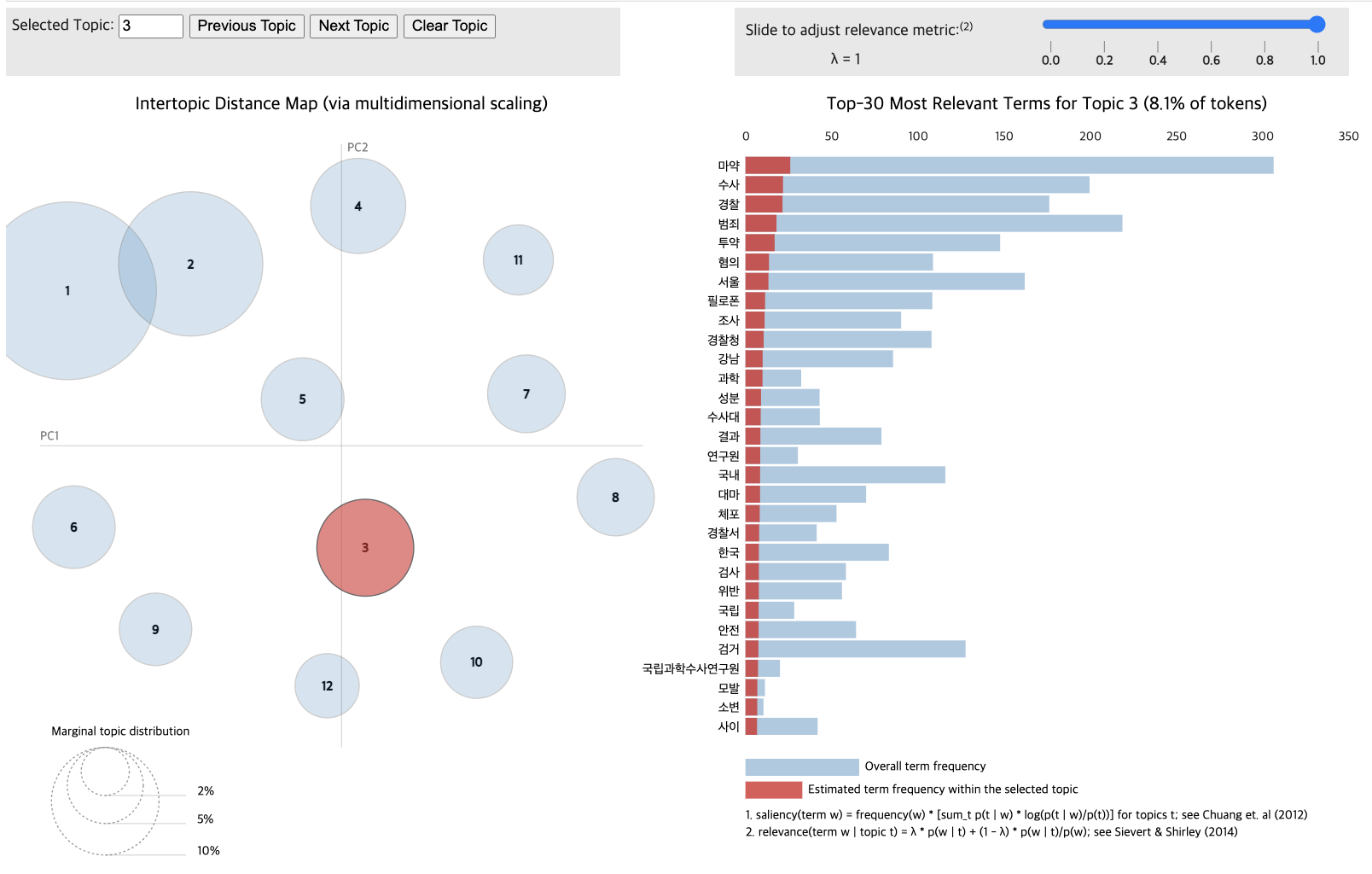
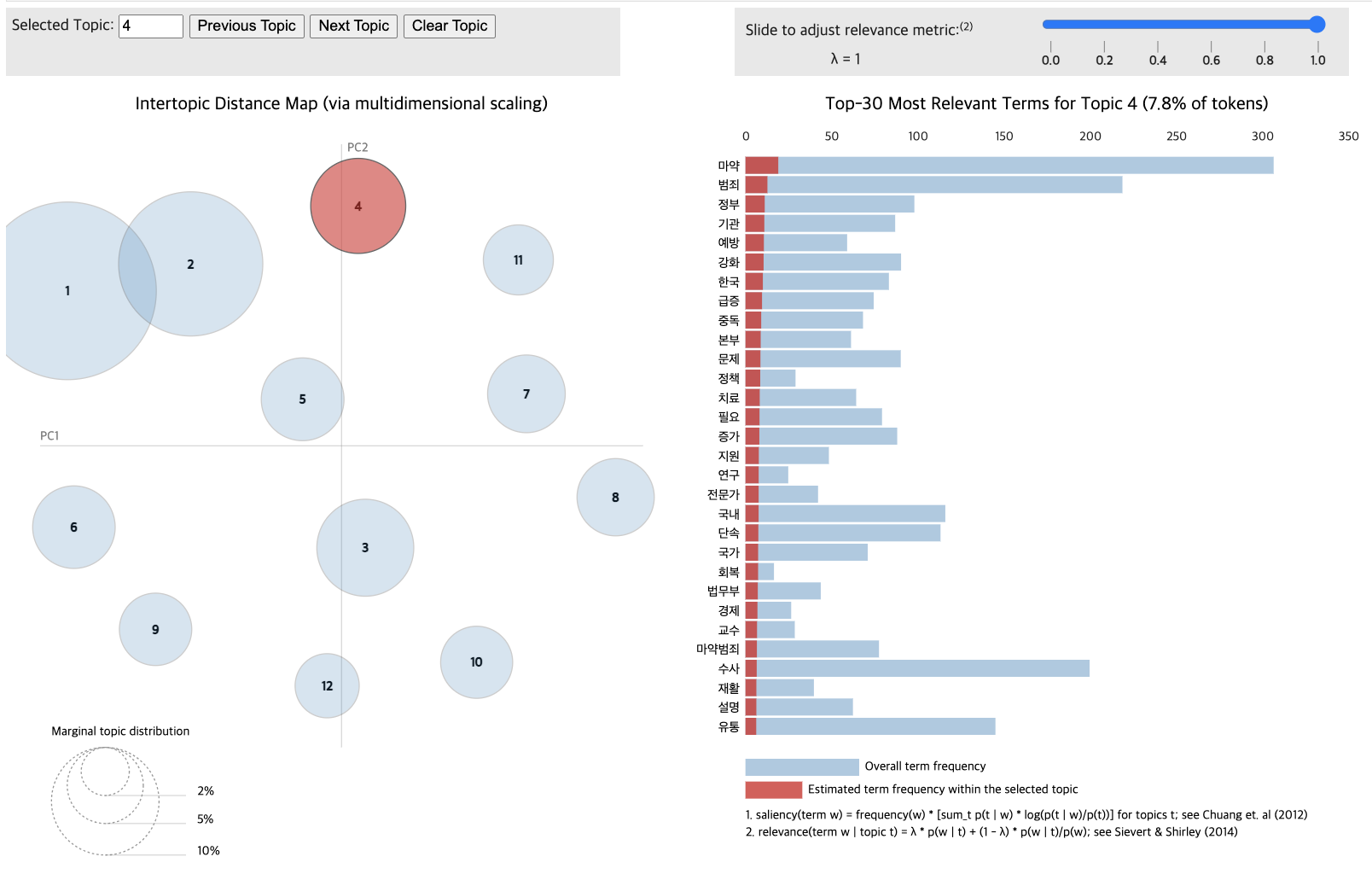

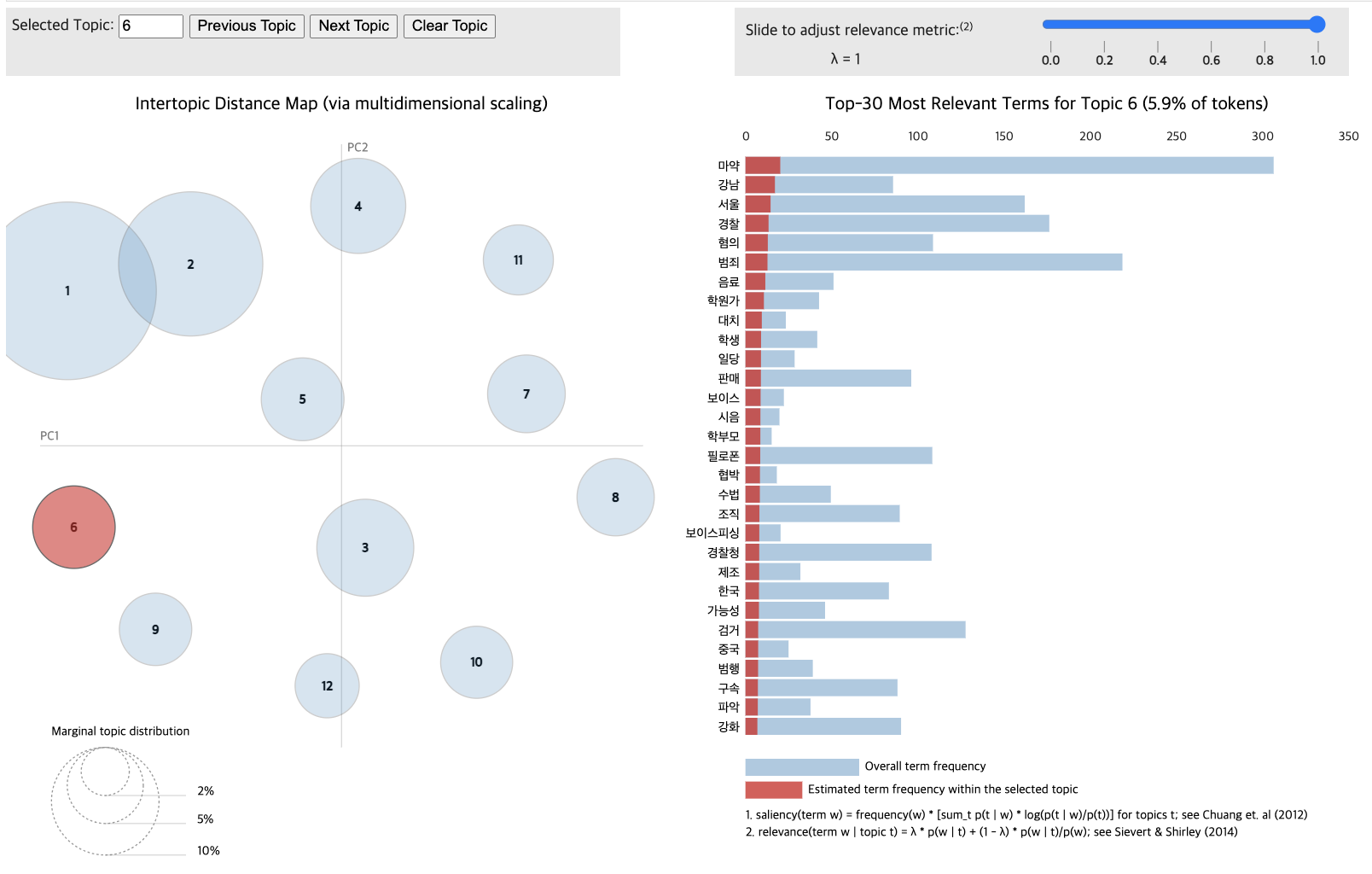
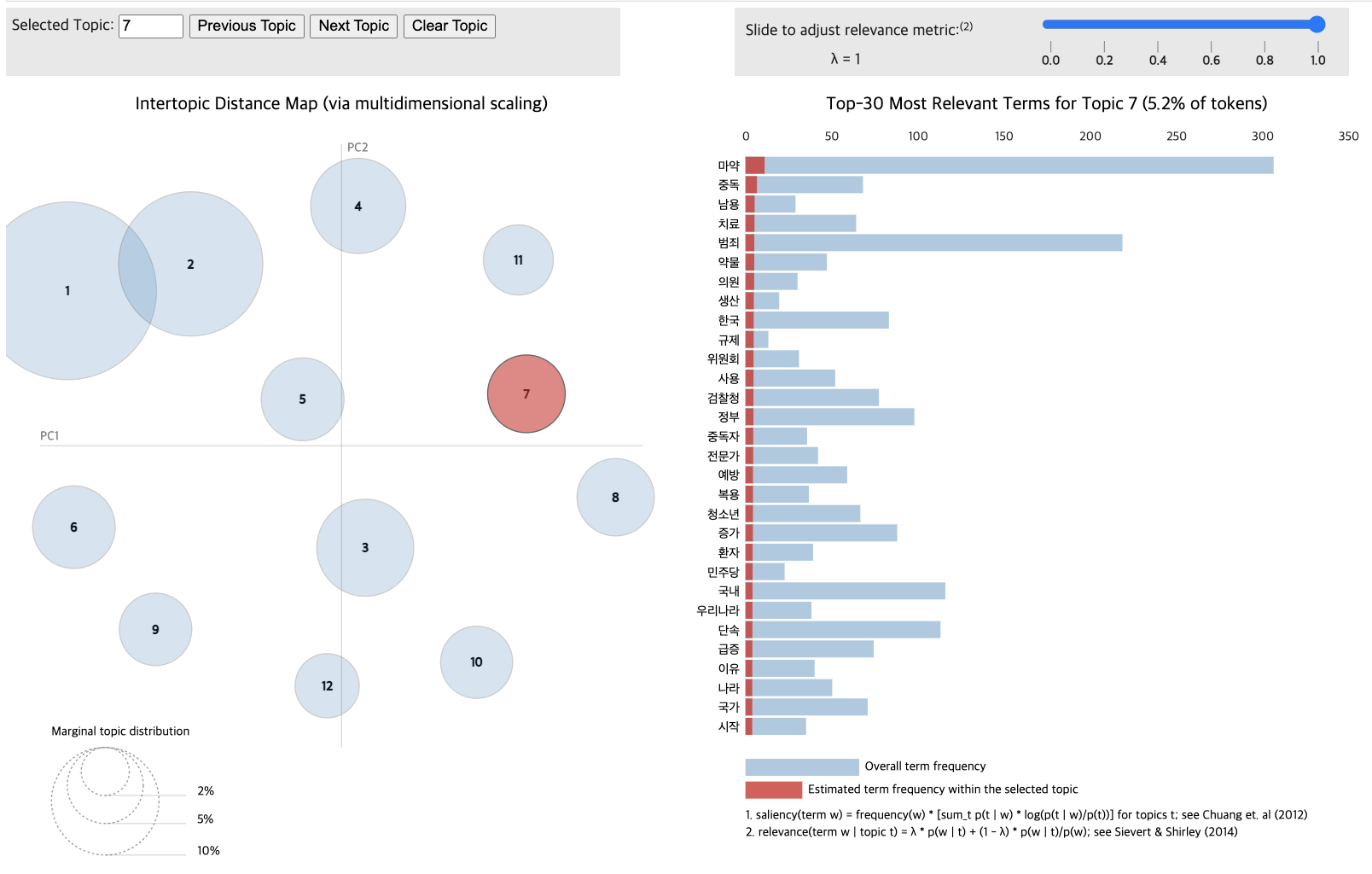
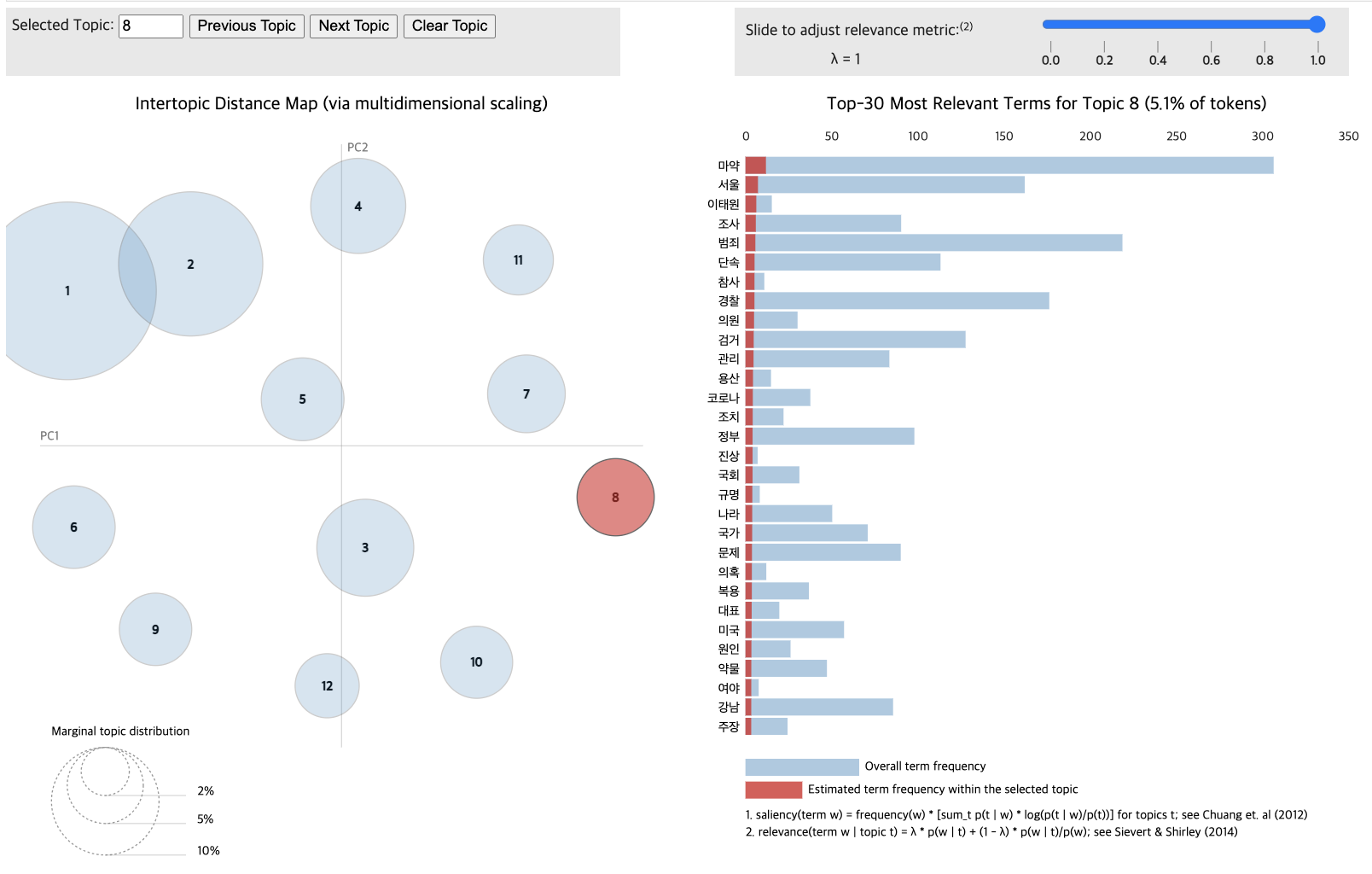
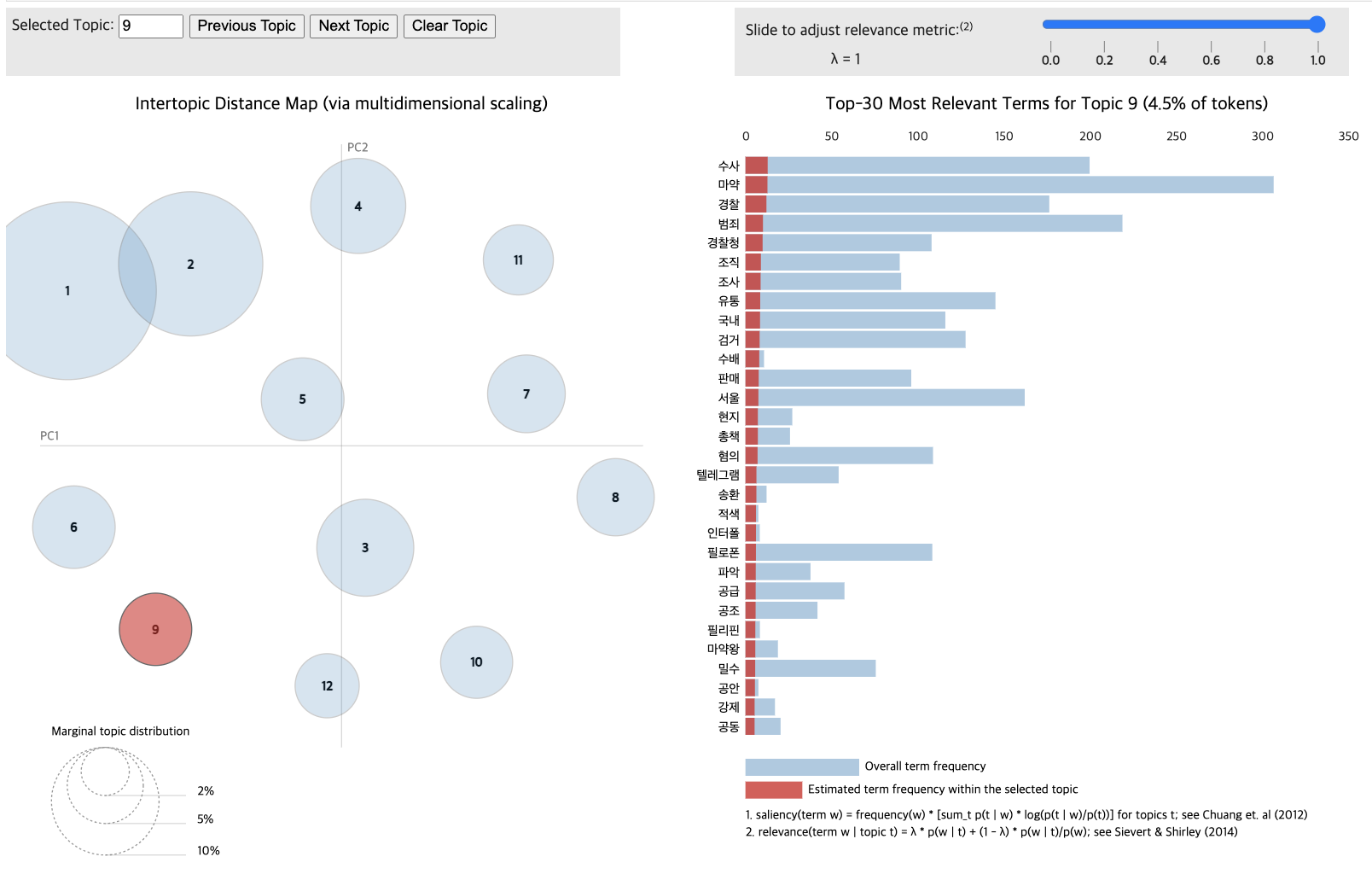



pyLDAvis.display(vis_data_with)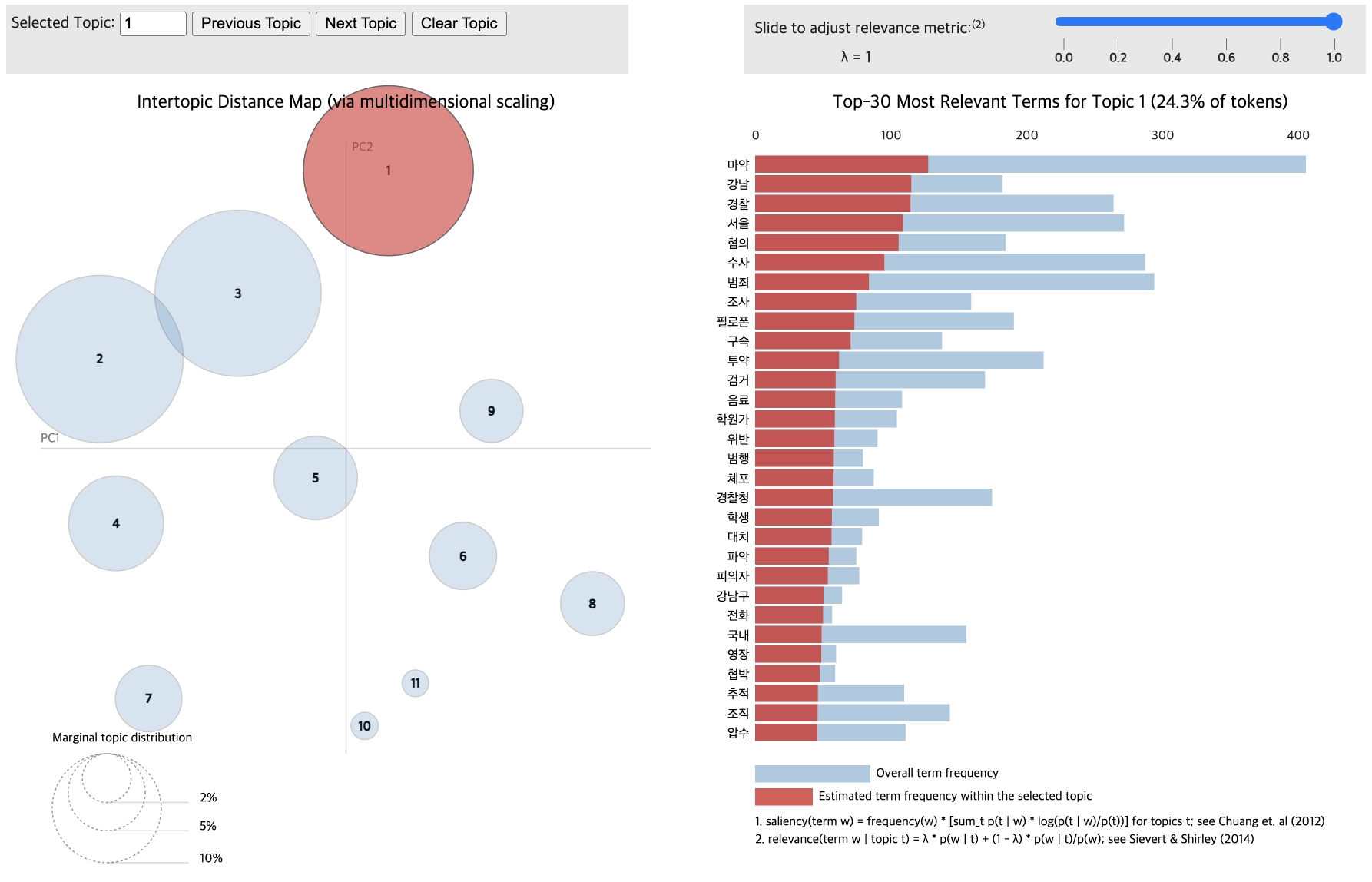
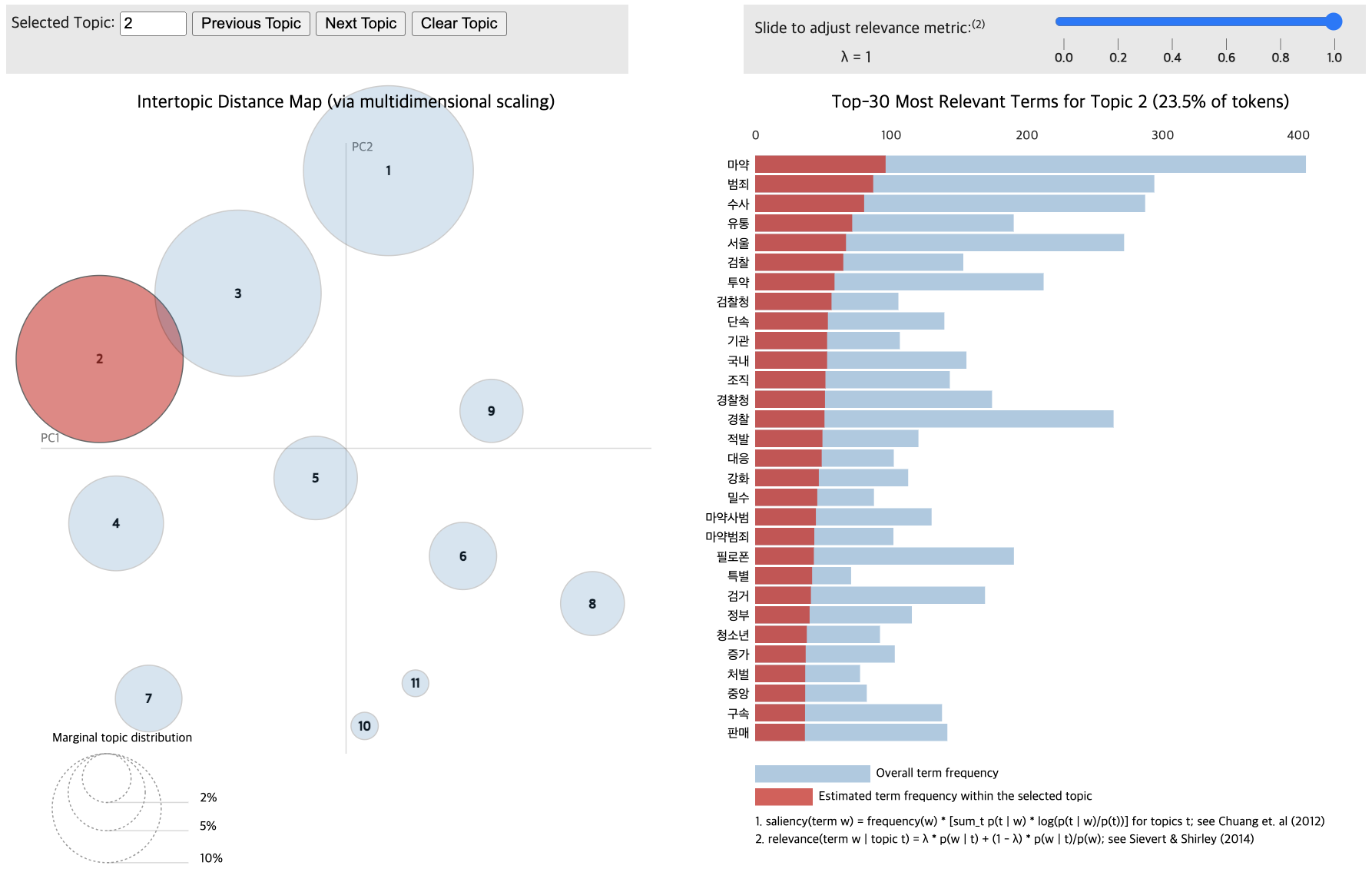
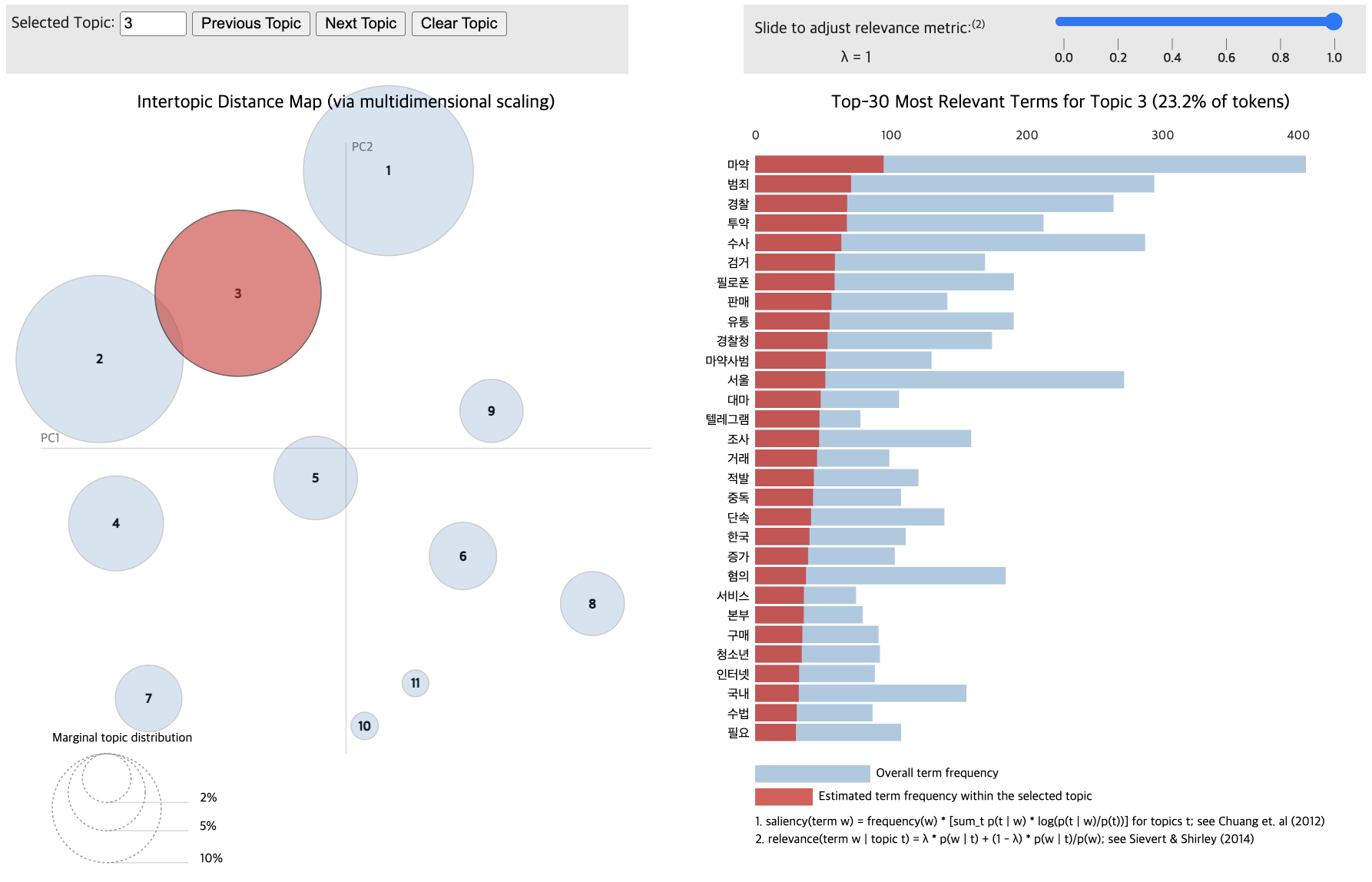
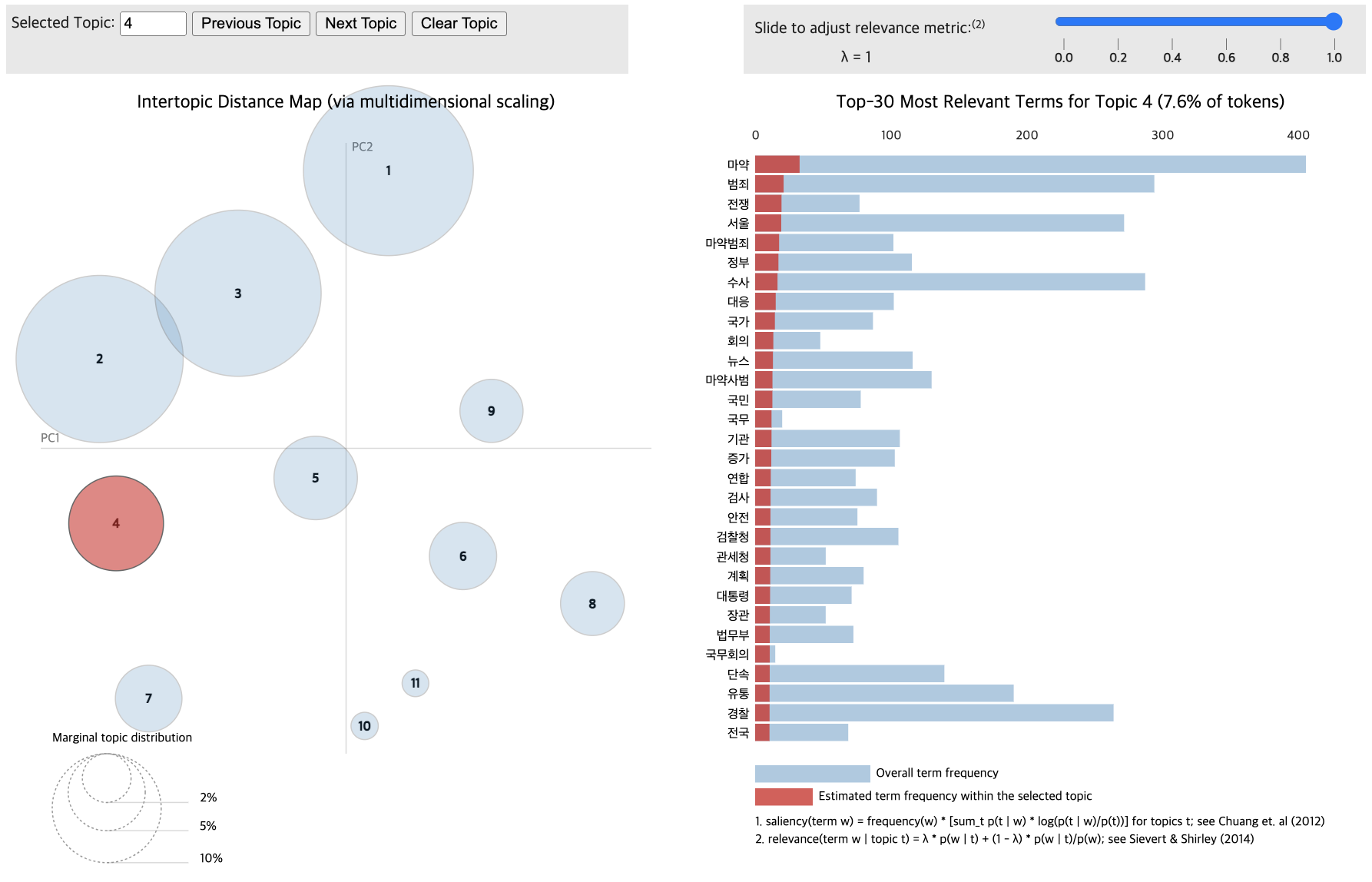
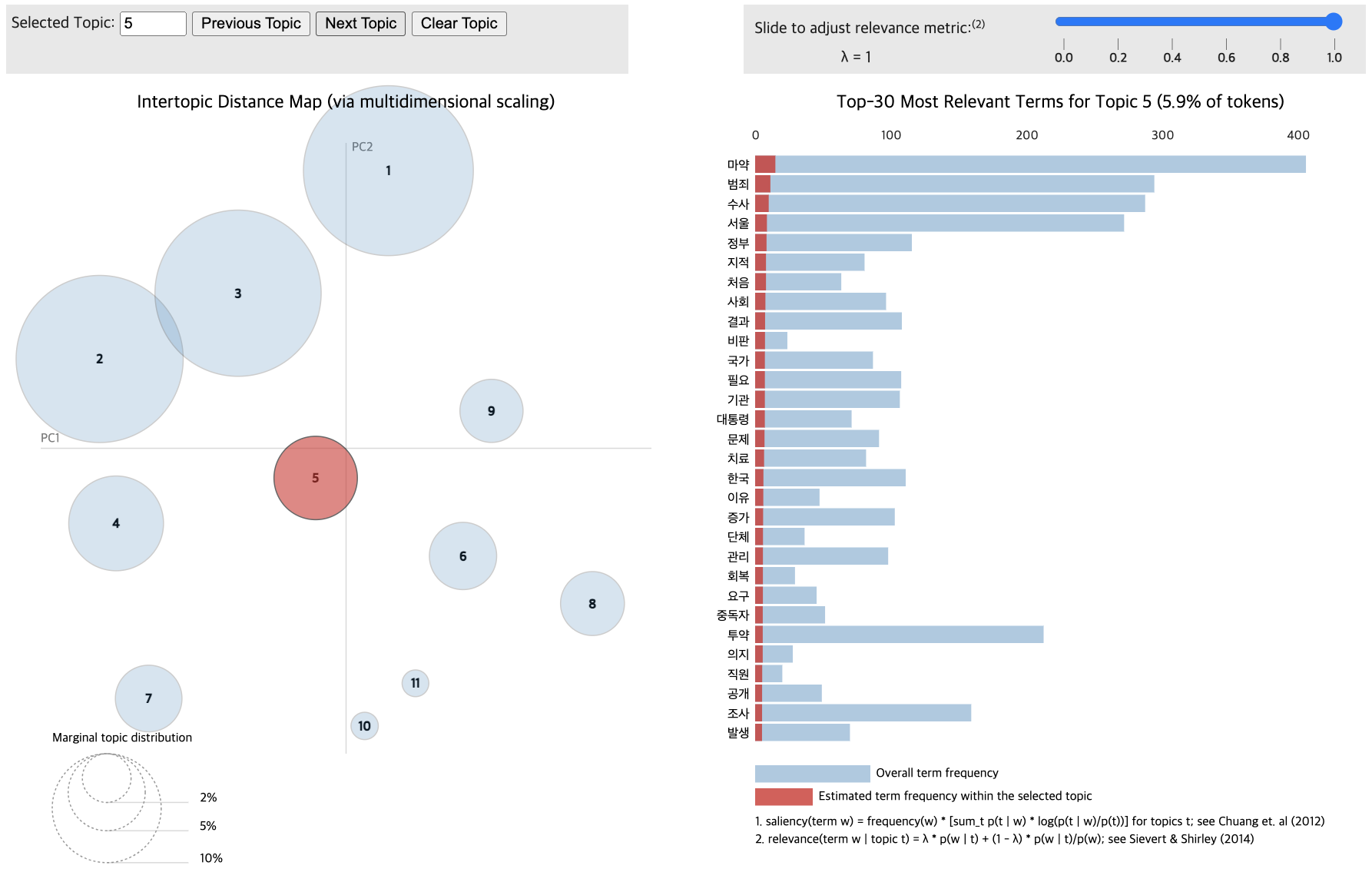

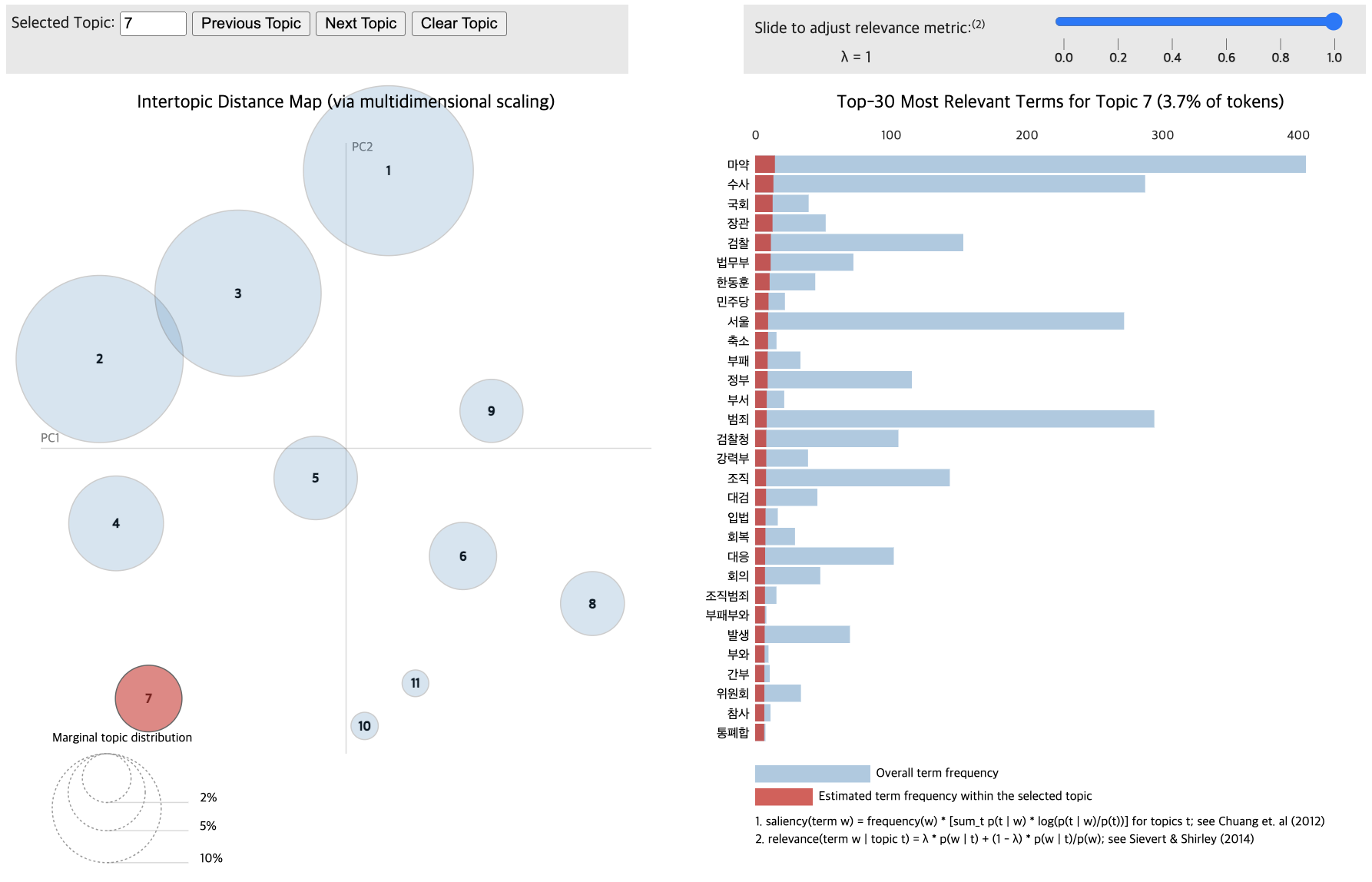

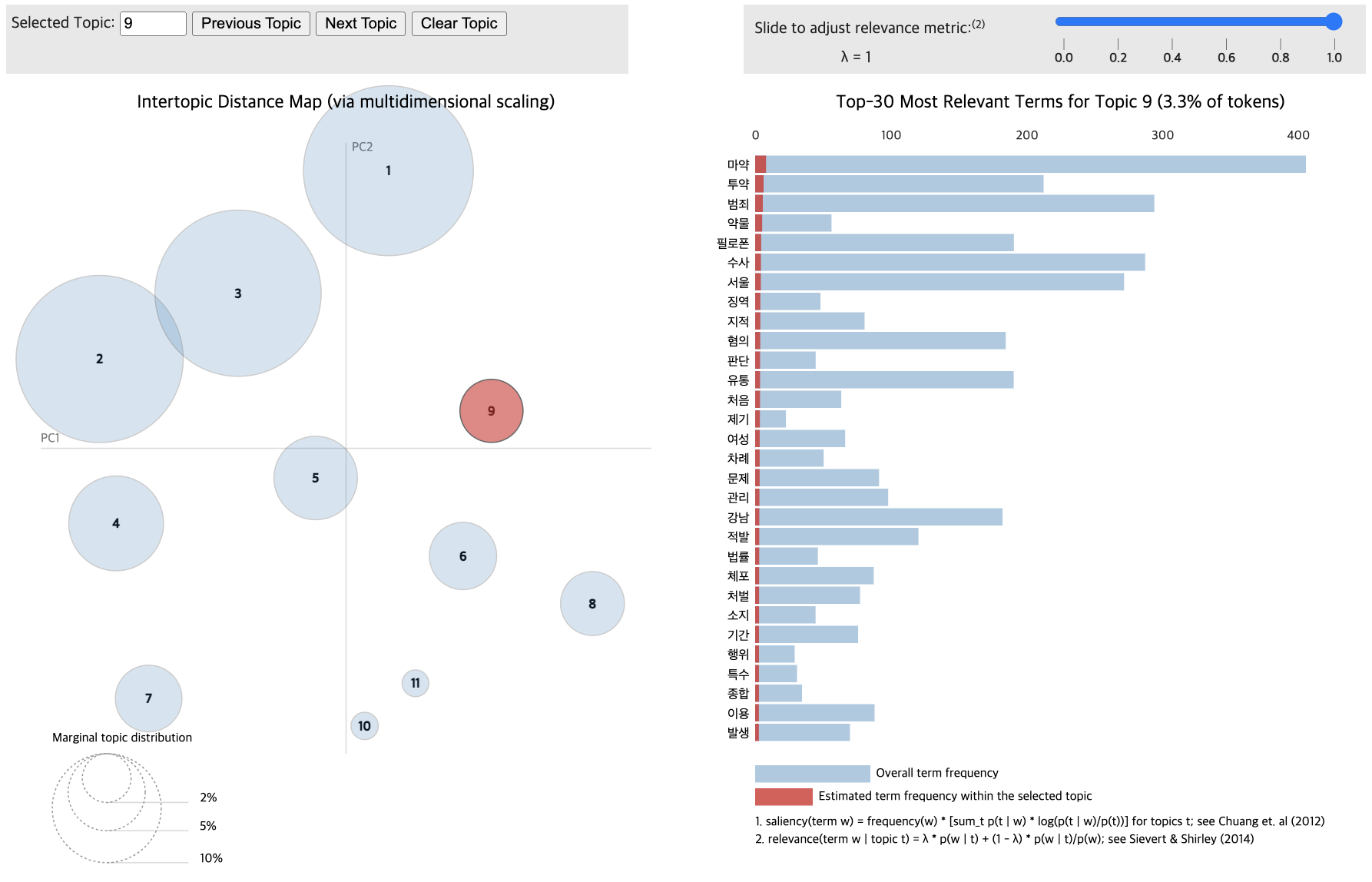
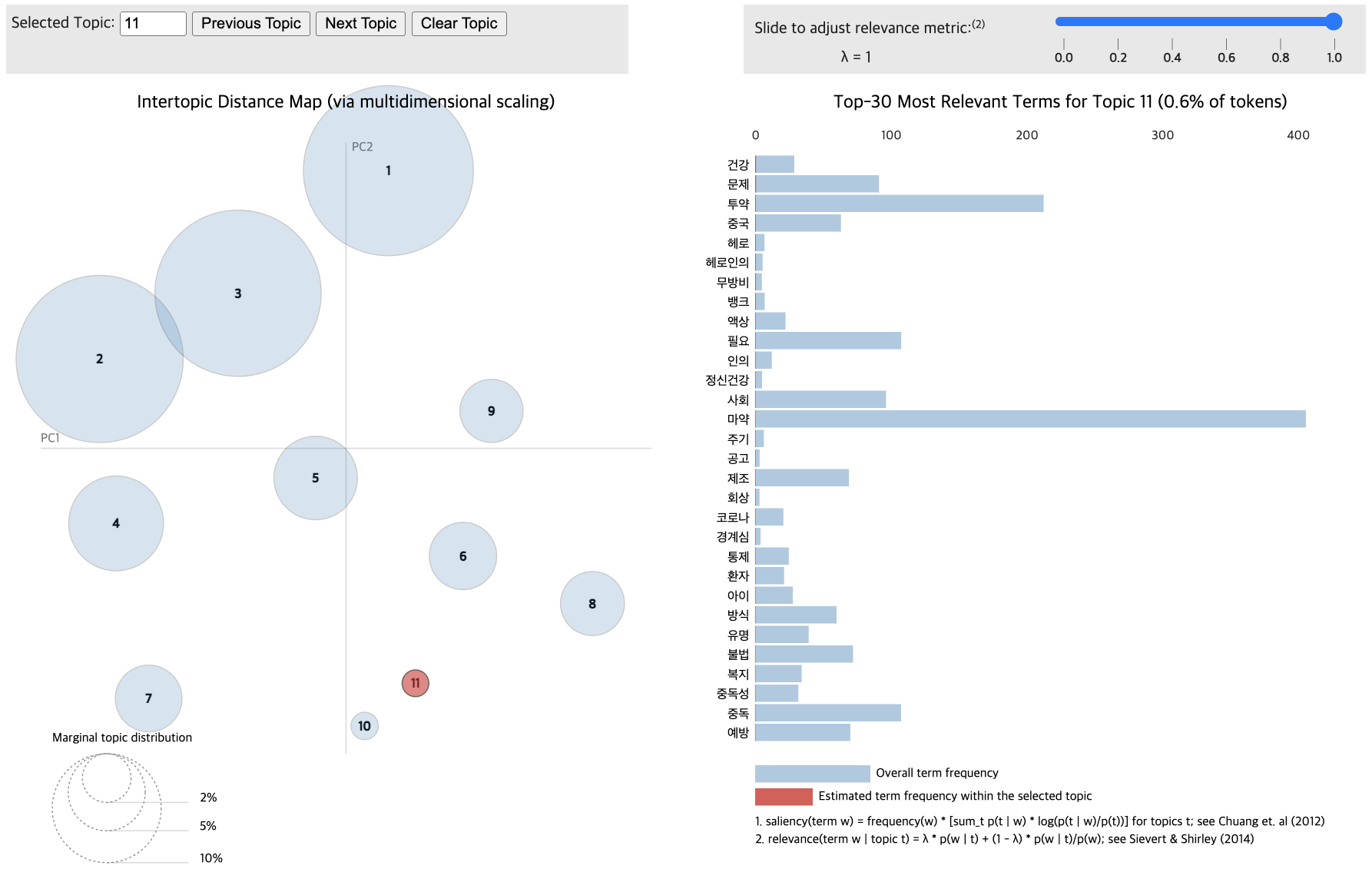
Topic differentiation between low and high-comment groups proved challenging.
Therefore, TF-IDF was used to compare characteristic keyword differences between groups.
import pandas as pd
from gensim.corpora import Dictionary
from gensim.models import TfidfModel
import numpy as np
# Merge the two dictionaries
merged_dictionary = Dictionary(documents=data_without['processed'].tolist() + data_with['processed'].tolist())
# Convert the original corpora to the merged dictionary
corpus_data_without_merged = [merged_dictionary.doc2bow(doc) for doc in data_without['processed']]
corpus_data_with_merged = [merged_dictionary.doc2bow(doc) for doc in data_with['processed']]
# Update the TfidfModels
tfidf_data_without = TfidfModel(corpus_data_without_merged)
tfidf_data_with = TfidfModel(corpus_data_with_merged)
# Convert the corpus to a TF-IDF representation
corpus_tfidf_data_without_merged = tfidf_data_without[corpus_data_without_merged]
corpus_tfidf_data_with_merged = tfidf_data_with[corpus_data_with_merged]
# Calculate the average TF-IDF scores for each term in the given corpus
def calculate_avg_tfidf(tfidf_corpus, dictionary):
avg_tfidf = np.zeros(len(dictionary))
for doc in tfidf_corpus:
for term_id, tfidf_score in doc:
avg_tfidf[term_id] += tfidf_score
avg_tfidf /= len(tfidf_corpus)
return avg_tfidf
# Calculate average TF-IDF scores for each dataset
avg_tfidf_data_without = calculate_avg_tfidf(corpus_tfidf_data_without_merged, merged_dictionary)
avg_tfidf_data_with = calculate_avg_tfidf(corpus_tfidf_data_with_merged, merged_dictionary)
# Calculate the difference in average TF-IDF scores between the two datasets
tfidf_diff = avg_tfidf_data_with - avg_tfidf_data_without
# Sort the terms based on the difference in their average scores (higher in data_with)
sorted_indices = np.argsort(tfidf_diff)[::-1]
# Print the terms with their average TF-IDF scores in both groups and their difference
print(f"{'Term':<40}{'Group A':<10}{'Group B':<10}{'Difference':<10}")
print("-" * 50)
for i in sorted_indices[:40]: # Display the top 40 terms
term = merged_dictionary[i]
group_a_score = avg_tfidf_data_without[i]
group_b_score = avg_tfidf_data_with[i]
diff = tfidf_diff[i]
print(f"{term:<40}{group_a_score:<10.4f}{group_b_score:<10.4f}{diff:<10.4f}")--------------------------------------------------
대치 0.0050 0.0100 0.0050
브리핑 0.0038 0.0081 0.0043
대치동 0.0043 0.0079 0.0036
자녀 0.0031 0.0066 0.0035
학원가 0.0068 0.0102 0.0034
강남구청역 0.0014 0.0047 0.0033
한동훈 0.0037 0.0068 0.0031
구청 0.0019 0.0049 0.0030
강남 0.0109 0.0139 0.0030
행사 0.0030 0.0060 0.0030
마약음료 0.0037 0.0067 0.0030
협박 0.0042 0.0071 0.0029
안내문 0.0009 0.0038 0.0029
호텔 0.0010 0.0039 0.0029
부모 0.0033 0.0061 0.0028
시음 0.0045 0.0073 0.0028
지시 0.0056 0.0084 0.0027
범행 0.0066 0.0093 0.0027
동훈 0.0000 0.0027 0.0027
아르바이트 0.0026 0.0053 0.0027
음료 0.0072 0.0099 0.0026
음료수 0.0035 0.0061 0.0026
강남구 0.0056 0.0082 0.0026
학원 0.0035 0.0061 0.0026
번호 0.0019 0.0044 0.0026
총기류 0.0012 0.0038 0.0025
공범 0.0040 0.0066 0.0025
대치역 0.0015 0.0040 0.0025
주택가 0.0015 0.0040 0.0025
전화 0.0044 0.0068 0.0024
우유 0.0012 0.0036 0.0024
피해자 0.0043 0.0066 0.0024
작곡가 0.0015 0.0039 0.0024
피의자 0.0059 0.0082 0.0023
대통령실 0.0025 0.0048 0.0023
계획 0.0068 0.0091 0.0023
접수 0.0018 0.0040 0.0023
제조 0.0052 0.0075 0.0023
보이스피싱 0.0046 0.0068 0.0023
마포 0.0019 0.0042 0.0023
- Code calculates TF-IDF score differences between datasets, ranking top 40 keywords by B-A difference to show B's distinctive terms.
- Analysis shows B's keywords ('한동훈') indicate political content; terms like '학원가', '강남', '마약음료' suggest high engagement on specific incident.
- Due to minimal differences, different approach needed.
import pandas as pd
import numpy as np
from gensim.models import Word2Vec
# Combine the preprocessed text from both groups
combined_text = data_without['processed'].tolist() + data_with['processed'].tolist()
# Train a Word2Vec model using both datasets
model = Word2Vec(sentences=combined_text, vector_size=100, window=5, min_count=1, workers=4)
# Calculate the average word embeddings for each article in both groups
def average_word_embeddings(text, word2vec_model):
embeddings = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]
if embeddings:
return np.mean(embeddings, axis=0)
else:
return np.zeros(word2vec_model.vector_size)
data_without['avg_word_embeddings'] = data_without['processed'].apply(average_word_embeddings, word2vec_model=model)
data_with['avg_word_embeddings'] = data_with['processed'].apply(average_word_embeddings, word2vec_model=model)
# Calculate the average word embeddings for both groups
group_a_avg = np.mean(np.vstack(data_without['avg_word_embeddings']), axis=0)
group_b_avg = np.mean(np.vstack(data_with['avg_word_embeddings']), axis=0)
# Get all unique keywords from both groups
keywords = set()
for text in combined_text:
keywords.update(text)
keywords = list(keywords)
keyword_vectors = np.vstack([model.wv[keyword] for keyword in keywords])
# Calculate the similarity scores between the keywords and the average word embeddings for both groups
keyword_scores_a = np.dot(keyword_vectors, group_a_avg)
keyword_scores_b = np.dot(keyword_vectors, group_b_avg)
# Calculate the difference in similarity scores between the two groups for each keyword
keyword_diffs = keyword_scores_b - keyword_scores_a
# Sort the keywords based on the difference in their embeddings (higher in data_with)
sorted_indices = np.argsort(keyword_diffs)[::-1]
# Print the keywords with their similarity scores in both groups and their difference
print(f"{'Term':<40}{'Group A':<10}{'Group B':<10}{'Difference':<10}")
print("-" * 50)
count = 0
for i in sorted_indices:
if count >= 40: # Display the top 20 terms
break
term = keywords[i]
group_a_score = keyword_scores_a[i]
group_b_score = keyword_scores_b[i]
diff = keyword_diffs[i]
print(f"{term:<40}{group_a_score:<10.4f}{group_b_score:<10.4f}{diff:<10.4f}")
count += 1--------------------------------------------------
서울 20.0186 20.2811 0.2625
마약 19.9555 20.2072 0.2516
조사 20.2466 20.4975 0.2509
경찰 19.4546 19.6993 0.2447
국내 19.8701 20.1141 0.2440
강남 17.6640 17.9077 0.2436
경찰청 19.3011 19.5442 0.2431
범죄 19.1094 19.3474 0.2380
수사 19.0546 19.2894 0.2348
투약 18.5684 18.7984 0.2300
필로폰 18.4169 18.6453 0.2284
검거 18.4139 18.6416 0.2277
혐의 18.0374 18.2643 0.2268
문제 18.3365 18.5613 0.2248
유통 18.1668 18.3897 0.2228
조직 18.0375 18.2597 0.2223
판매 17.8005 18.0196 0.2191
단속 17.8242 18.0424 0.2182
검찰 17.6269 17.8441 0.2172
필요 17.6173 17.8338 0.2166
정부 17.4035 17.6172 0.2137
구속 17.1199 17.3335 0.2136
한국 17.5032 17.7166 0.2134
국가 17.3216 17.5341 0.2125
기관 17.4172 17.6296 0.2124
중독 17.2708 17.4822 0.2115
제공 16.6046 16.8142 0.2096
사회 17.1209 17.3304 0.2095
관리 16.7447 16.9519 0.2071
결과 16.8111 17.0179 0.2068
미국 16.7220 16.9274 0.2054
뉴스 16.0703 16.2724 0.2021
적발 16.3994 16.6012 0.2018
강화 15.9237 16.1212 0.1975
마약사범 16.0158 16.2121 0.1963
국제 15.8801 16.0749 0.1947
검사 15.7539 15.9475 0.1935
설명 15.5910 15.7823 0.1913
증가 15.3379 15.5254 0.1876
거래 15.1765 15.3618 0.1853
The code above uses Word2Vec to identify keywords emphasized more in group B versus group A.
It calculates keyword similarity scores and mean word embeddings between groups to identify terms more prominent in group B.
While differences exist, they were deemed too minimal or insufficiently supported to be considered significant characteristics.
Data preprocessing and rationale for Kkma analyzer and POS selection:
- Attempted to identify distinguishing features between high and low-comment articles using article content
- Insufficient explanatory power to extract significant differences between groups through article content analysis